セッション層、プレゼンテーション層、アプリケーション層の仕事
- 代表的なアプリケーション・プロトコル
- HTTP - Webの情報をやり取りするプロトコル
- DNS
- POP、SMTP、IMAP
- アプリケーション層で動作する機器
- セッション管理やコネクション管理の設計は慎重に
セッション層、プレゼンテーション層、アプリケーション層の3つはアプリケーション・プロトコルとしてすべて同期して動作します。セッション層は、通信の開始から終了までの手順を決める層で、アプリケーション間で論理的な通信路(コネクション)を確立し、通信ができる状態にします。WindowsやSQLなどがこの層にあたります。
プレゼンテーション層は、上位層であるアプリケーション層にデータを提供するために情報の符号化や変換を行います。画像フォーマットでJPEGやPICT、動画フォーマットでMPEGなどを表現するのがプレゼンテーション層になります。
アプリケーション層はアプリケーション(メールやWWWブラウザなど)に合わせて通信を行えるように定めている部分です。最上位層に位置するアプリケーション層はユーザが直接接する部分で、コンピュータなどが通信相手を識別しネットワーク経由で送受信を行うものです。
ここでは一般的なアプリケーション・プロトコルについて、ネットワークの動作を中心に見ていきましょう。
代表的なアプリケーション・プロトコル
それぞれのアプリケーションでは、アプリケーション特有の通信処理が必要になります。この通信処理を行うのがアプリケーション・プロトコルです。代表的なアプリケーション・プロトコルには以下のようなものがあります。
| プロトコル | 機能 |
|---|---|
| HTTP | WebサーバーとWebブラウザ間でWebページのデータをやり取りを行う。 |
| POP、SMTP、IMAP | メールの送受信を行う。 |
| FTP | FTPサーバーとFTPクライアント間でファイルのやり取りを行う。 |
| Telnet、SSH | サーバーに遠隔からログインし操作を行う。 |
| DNS | URLとIPアドレスを相互変換する。 |
| DHCP | ネットワークに繋がるノードにIPアドレスを割り当てる。 |
| NTP | ネットワークに繋がるノードの時刻を同期する。 |
| SNMP | ネットワーク機器の管理機能を提供する。 |
HTTP - Webの情報をやり取りするプロトコル
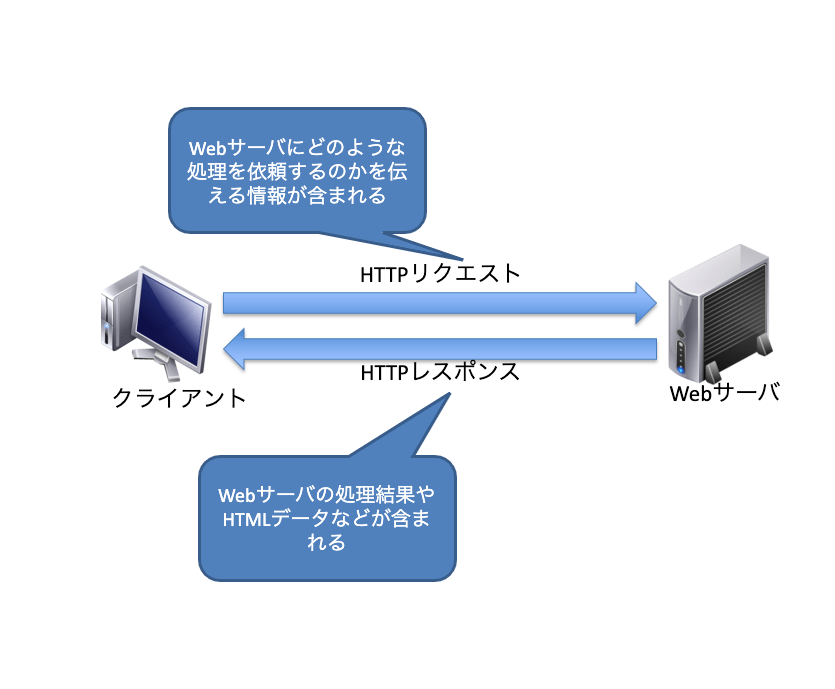
普段何気なく閲覧しているWebサイトですが、WebブラウザとWebサーバの間では、HTTP(HyperText Transfer Protocol)というプロトコルを使って情報のやり取りを行っています。
ユーザがWebブラウザからWebアクセスを開始すると、WebブラウザはWebサーバに情報の要求を行います。要求を受けたWebサーバは、その情報をWebブラウザへ返信します。情報を受信したWebブラウザは、その情報をもとに内容を表示します。
Webページを表示するまでの流れ
実際にWebページを表示させる流れを見ていきましょう。
WebブラウザにURLを入力
Webページを見るときに、Webブラウザのアドレスバーにアドレスを入力します。このアドレスをURL(Uniform Resource Locator)といいます。URLの基本的な既述方法は「http://ドメイン名/フォルダ名/ファイル名」というように既述されます。
名前解決を実施
WebブラウザにURLを入力すると、WebブラウザはURLの「:」以下に書かれたWebサーバの指定した場所にアクセスして、情報を取得しようとします。Webブラウザに「http://itbook.info/index.html」と入力した場合、まずDNSを使用してドメイン名からIPアドレスを調べます。 の動作を「名前解決」と呼びます。名前解決はWebブラウザが行う訳ではなく、OSが提供しているリゾルバが担当します。DNSについては後ほど詳しく解説していきます。
WebサイトのURLを送信
無事に名前解決ができたら、Webブラウザは該当のIPアドレスのWebサーバへアクセスします。インターネットはTCP/IP通信が基本です。当然WebアクセスもTCP/IP通信で行います。そこでまずは、WebサーバとTCPのコネクションを確立します。Webブラウザから、OS上のTCPを処理するソフトへ「○○というデータが欲しい」という「HTTPリクエストメッセージ」を渡します。それを受けて、TCP処理ソフトが、Web(HTTP)のポート番号「80」宛にTCP接続を行います。受信側(Webサーバ)では、データを受信すると、パケットからHTTPリクエストを取り出し、Webサーバへと渡します。HTTPリクエストを受け取ったWebサーバは、HTTPリクエストの中身を確認して該当の情報(HTMLデータ)をHTTPレスポンスで返信します。
このようにHTTPは、リクエスト(要求)とレスポンス(応答)の2つのメッセージでやりとりを行います。WebブラウザからWebサーバへのメッセージが「HTTPリクエスト」、WebサーバからWebブラウザへのメッセージが「HTTPレスポンス」です。
受信したHTMLファイルを確認
HTMLデータを受け取ったWebブラウザは、中身を上から順番に解析していきます。画像や動画などを掲載しているWebサイトの場合、HTMLデータの中に画像や動画が保存されているWebサーバへのリンクの情報(URL)が記載されています。HTMLデータの中にURLが見つかった場合、そのURLの情報をWebサーバにHTTPリクエストを送信して情報を取得していきます。画像や動画などを多く掲載しているWebサイトの場合、この動作を繰り返します。
このようにHTTPリクエストとHTTPレスポンスを繰り返して取得した情報を組み合わせて、最終的にWebページを表示します。
HTTPメッセージ
WebサーバーとWebブラウザでやり取りされるものをHTTPメッセージと呼び、HTTPリクエストとHTTPレスポンスの2種類があります。
HTTPリクエスト
HTTPリクエストの中身は大きく以下の3つに分けられます。
- リクエスト行
- メッセージヘッダー
- メッセージボディ
リクエスト行には、Webサーバにどのような処理を依頼するのかを伝える情報が含まれます。例えばデータを送ってほしいという命令であれば、「GET /index.html HTTP/1.1」といった情報がセットされます。この時の「GET」をメソッド、「/index.html」が送信要求のデータ、「HTTP/1.1」はWebブラウザが対応しているHTTPのバージョンを意味します。
【GET /index.html HTTP/1.1】メソッド
Webサーバへ要求する操作を表すメソッドと呼び、GETの場合は「データの送信要求」を意味します。
HTTPリクエストのメソッドの種類には以下のようなものがあります。
| メソッド | 説明 |
|---|---|
| CONNECT | トンネル確立を要求 |
| DELETE | データ削除の要求 |
| GET | データの送信要求 |
| HEAD | メッセージヘッダの内容を問い合わせ |
| OPTIONS | サポートするオプションの問い合わせ |
| POS | サーバにデータを送信 |
| PUT | ファイルのアップロード |
| TRACE | 経由するサーバに応答要求 |
メッセージヘッダーは対応している言語やエンコードの方式などの情報がセットされます。メッセージボディはWebサーバから情報をもらうのではなく、WebブラウザがWebサーバにデータを送るときに場合に使用します。

HTTPレスポンス
HTTPレスポンスも大きく以下の3つに分けられます。
- ステータス行
- メッセージヘッダー
- メッセージボディ
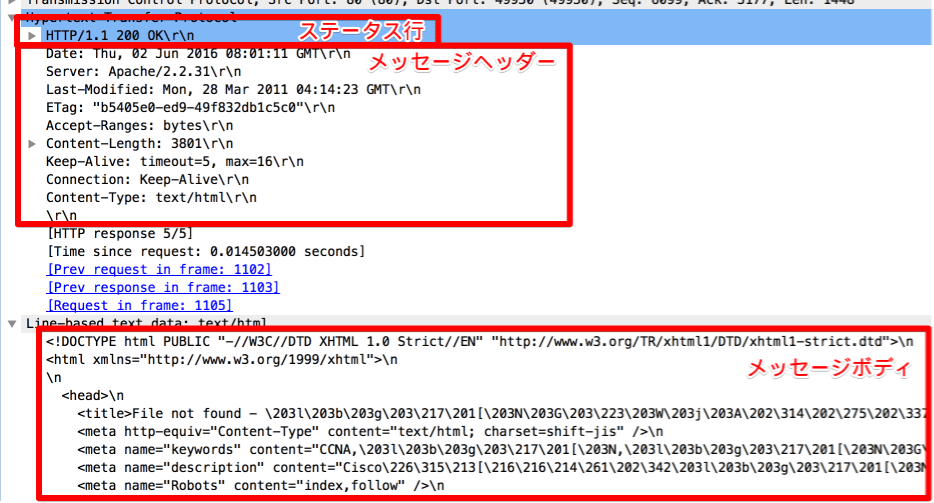
ステータス行にはWebサーバの処理結果(ステータスコード)がセットされます。処理が完了した場合は「HTTP/1.1 200 OK」といった情報がセットされます。ステータスコードは3桁の数字で表して、「200」であれば処理成功を意味します。
Webアクセスをしていて「404 Not Found」というメッセージを見たことがある方も多いかもしれません。これはデータが見つからないことを意味しています。
HTTPレスポンスのステータスコードの種類には以下のような種類があります。
| ステータスコード | 説明 |
|---|---|
| 100 | データに続きがあるため再要求 |
| 101 | 指定プロトコルで再接続を要求 |
| 200 | リクエスト処理成功 |
| 201 | ファイル作成成功 |
| 301 | データが別の場所に移動 |
| 302 | 一時的にデータは別の場所に移動 |
| 403 | データへのアクセス不可 |
| 404 | データが見つからない |
| 500 | サーバ内部のエラー |
| 503 | 一時的にサーバ処理不可 |
メッセージヘッダーにはWebブラウザやWebサーバの状態ややりとりする情報がセットされます。メッセージボディにはWebブラウザとWebサーバがやりとりするHTMLデータが入ります。
HTTPのバージョンによるTCPコネクションの違い
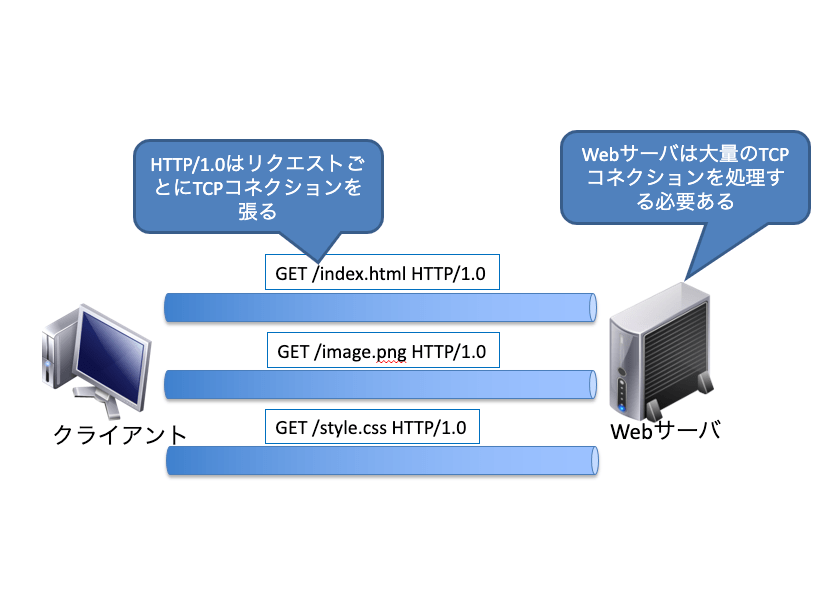
HTTPには「HTTP/1.0」と「HTTP/1.1」という2つのバージョンが多く利用されています。どちらを利用するかはWebサーバとWebブラウザの設定次第ですが、最近の主流は「HTTP/1.0」から「HTTP/1.1」に移行してきています。この2つのバージョンはTCPコネクションの使い方が異なっていて、それが原因でネットワークのトラブルに繋がることがありますので、しっかりと理解しておきましょう。
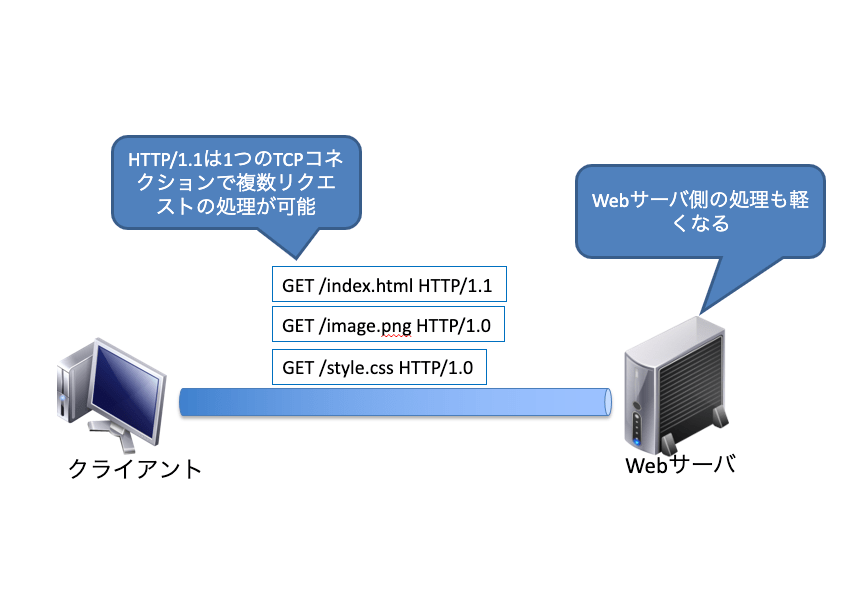
HTTP/1.0はリクエストごとにコネクションを張る
HTTP/1.0はリクエストごとにTCPコネクションを張ります。1つのWebサイトを見る場合でも、サイト内に複数のコンテンツがあれば、そのコンテンツごとにTCPコネクションを張ります。そのためTCPコネクション数が、当初見込んでいた数以上に増大する可能性があります。
HTTP/1.1は1つのコネクションで複数リクエストの処理が可能
HTTP/1.1はHTTP/1.0のコネクション数が増大する問題を解決するために、様々な仕様が盛り込まれました。HTTP/1.1では1度張ったTCPコネクションを使った複数のリクエストを処理すつことが可能です。
DNS
Webブラウザに「http://www.itbook.info/」と打ち込んでみると、拙サイトが表示されると思います。インターネットはTCP/IP通信ですので、この「http://www.itbook.info/」 という文字列を使って通信をするわけではなく、「http://www.itbook.info/」という文字列からWebサイトのIPアドレスを調べて、そのIPアドレス宛にWebアクセスを行っています。今回解説する「DNS(Domain Name System)」は、 「http://www.itbook.info/」という文字列から、 IPアドレスを調べるしくみのことをいいます。

DNSの役割
インターネットはTCP/IP通信ですので、各ノードにはIPアドレスが付与されて、IPアドレスを使ってお互いに通信を行います。Webアクセスも「192.168.1.1」というようにIPアドレスを指定して通信を行えば良いのですが、IPアドレスは数字の羅列のため少し分かりづらいです。そこで、人間にも分かるように、「ドメイン名(Domain Name)」と呼ばれる文字列でもアクセスが可能なようにしました。このドメイン名とIPアドレスを対応づけるしくみがDNSです。
DNSの基本動作
DNSの基本的な動作は、「ドメイン名に対応したIPアドレスを調べたいクライアントが、DNSサーバが保持しているドメイン名とIPアドレスの対応表に問い合わせて、目的のIPアドレスを調べる」ことです。クライアントPCからWebサイトへアクセスする場合を例に、DNSの動作を見ていきましょう。
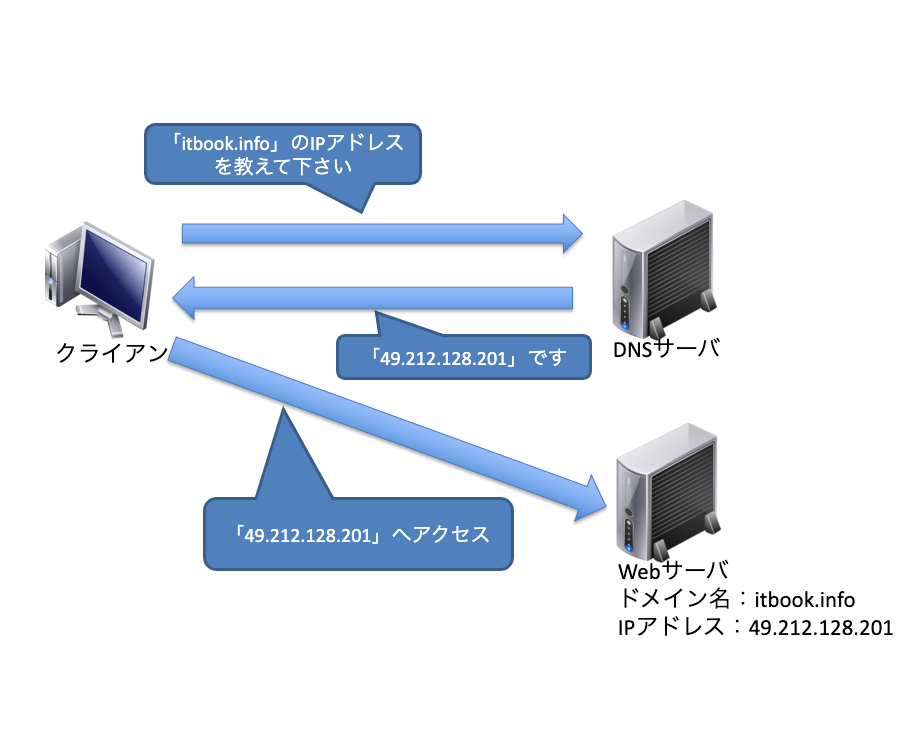
まず、Webブラウザから「http://www.itbook.info/」へアクセスを行います。するとWebブラウザは、「http://www.itbook.info/」に対応するIPアドレスをDNSを使って調べます。このドメイン名からIPアドレスを割り出す処理を「名前解決」と呼びます。IPアドレスが分かれば、後は対象のIPアドレスを持つWebサーバにアクセスを行います。
ドメイン名を使用する利点は、人間が理解しやすいという理由以外にも、もう1つの利点があります。 それは「サーバのIPアドレスが変わっても、アクセス元に影響を与えない」ということです。Webサーバを別の場所に移したり、別のサーバに引っ越したりして、IPアドレスが変わると、クライアントがドメイン名ではなくIPアドレスでアクセスしていると、クライアント全員にIPアドレスの変更を通知しなければなりません。しかし、ドメイン名でアクセスしていれば、ドメイン名に対応するIPアドレスの情報を変更するだけで済みます。
DNSの詳細動作
まず、WebブラウザやメールソフトがDNSサーバにIPアドレスの問い合わせをすると、各アプリケーションに含まれている「リゾルバ(resolver)」というプログラムが動作します。リゾルバとは、DNSサーバにホスト名を通知してIPアドレスの検索を依頼したり、その逆を依頼したりするクライアント側のプログラムのことです。
Webブラウザやメールソフトなどのアプリケーションからの指示で、リゾルバがDNSサーバへIPアドレス問い合わせのメッセージを送信します。このメッセージには、「www.itbook.infoに対するIPアドレスを教えて下さい」という内容が入っています。メッセージを受け取ったDNSサーバは、自分が持っている情報から対応するIPアドレスを探します。この情報のことを「ゾーン情報」と呼びます。
DNSサーバは対応するIPアドレスを応答メッセージに入れてリゾルバへと返信します。リゾルバは、受信したメッセージから内容を確認して、IPアドレスをアプリケーションに伝えます。こうすることで、WebブラウザやメールソフトがIPアドレスを認識し、通信が可能になります。
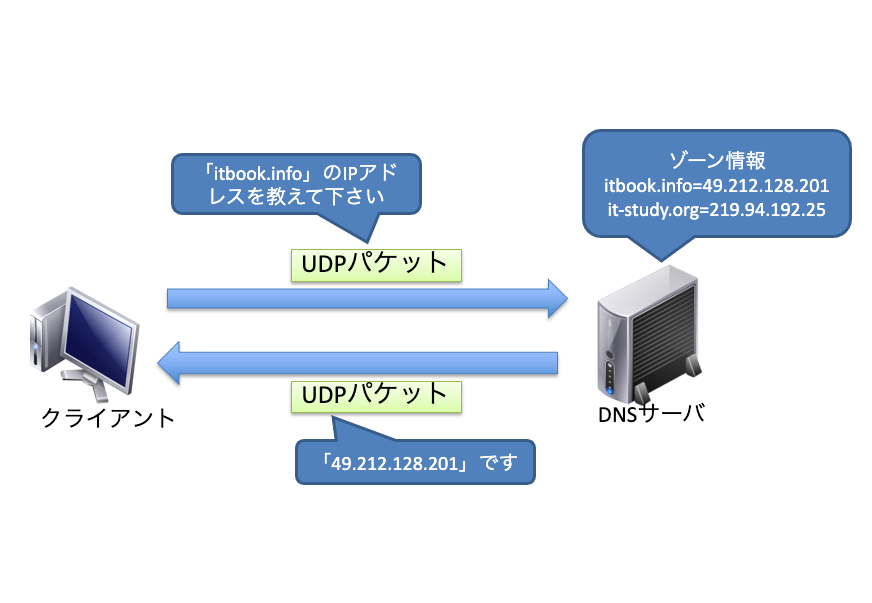
DNSの問い合わせのやり取りは、TCPを使って行うことも可能ですが、通常はUDPを使って行われます。DNSとのやり取りはパケットサイズが小さく、信頼性よりもレスポンスを重視することから、TCPよりもUDPの方が効率的であるためです。
ただし、DNSサーバとDNSサーバとがゾーン情報のファイル転送を行う場合は、TCPを使用します。ゾーン情報とは、IPアドレスやドメイン名の情報で、この情報をDNSサーバ同士で同期する場合は、効率性よりも信頼性を重視してTCPが使われます。
分散処理という考え方
インターネット上には非常に多くのドメインが存在して、すでに世界のドメイン数は1億8000万件を超えて現在も増え続けています。これほど多くのドメイン数を1台のDNSサーバでまかなうことは当然不可能です。そのため、インターネット上に多数のDNSサーバを置き、相互に連携してシステムを構成しています。
DNSサーバはリゾルバから問い合わせを受けると、自分のゾーン情報から答えを探して、もし答えがなければ別のDNSサーバに問い合わせて探してくれます。ドメイン名は「www.test.co.jp」のように「.(ドット)」で区切られています。これにはちゃんと理由があり、それぞれが階層を示していて、右側にある文字列ほど上位の階層であることを意味しています。これは、DNSサーバが「ルート・サーバ」と呼ばれる最上位層のDNSサーバを中心にツリー構造になっているためです。
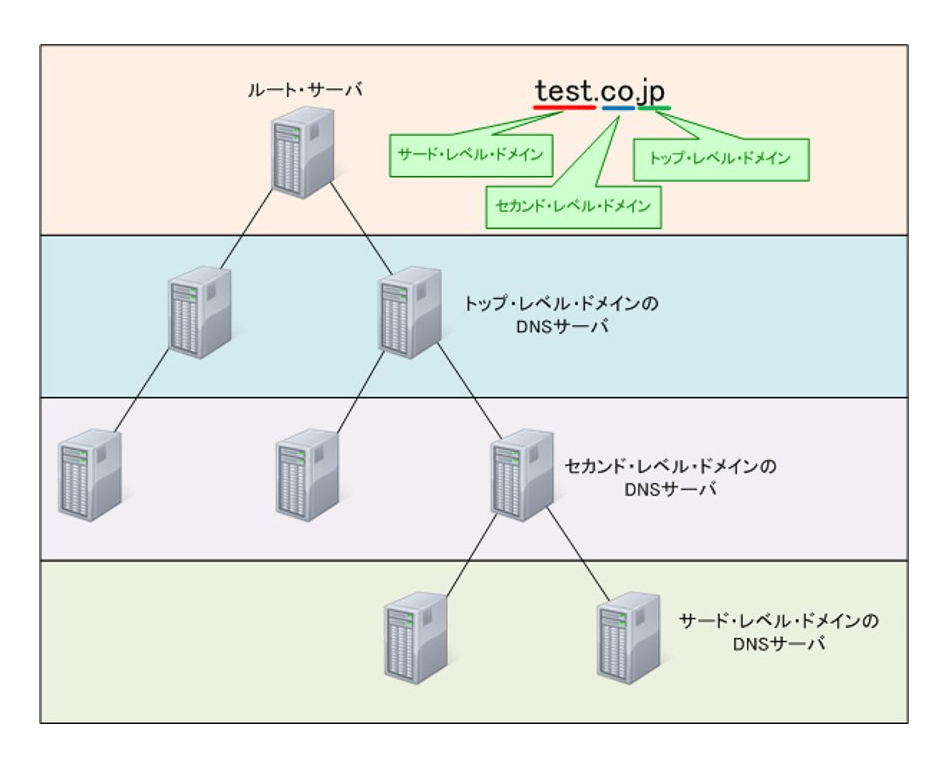
IPアドレス問い合わせ手順
リゾルバがDNSサーバへ、「www.test.co.jp」というドメインに対するIPアドレスを問い合わせる手順を見てみましょう。リゾルバはまず、最寄りのDNSサーバへ問い合わせを行います。このDNSサーバを「ローカル・サーバ」と呼びます。ローカル・サーバに情報があれば、リゾルバへ情報を返信します。もしローカル・サーバに情報が無い場合、ローカルサーバーは「ルート・サーバ」へ問い合わせを行います。
ルート・サーバは最下層である、「トップ・レベル・ドメイン」を管理するサーバです。 つまり「jp」を管理するDNSサーバのIPアドレスをローカル・サーバへと返信します。返信を受け取ったローカル・サーバは、「jp」を管理するDNSサーバのIPアドレスを知ることができたので、そのDNSサーバーへ問い合わせを行います。
「jp」ドメインを管理するサーバは下の階層(セカンダリ・レベル・ドメイン) の「co.jp」ドメインを管理するDNSサーバのIPアドレスをローカル・サーバへと返信します。ローカル・サーバは、「co.jp」を管理するDNSサーバ、「test.co.jp」を管理するDNSサーバと順に階層を下げていって目的のドメイン名の IPアドレスを調査します。
このように各DNSサーバが協調して分散処理を実施することで、データ管理や負荷の軽減を実現させています。
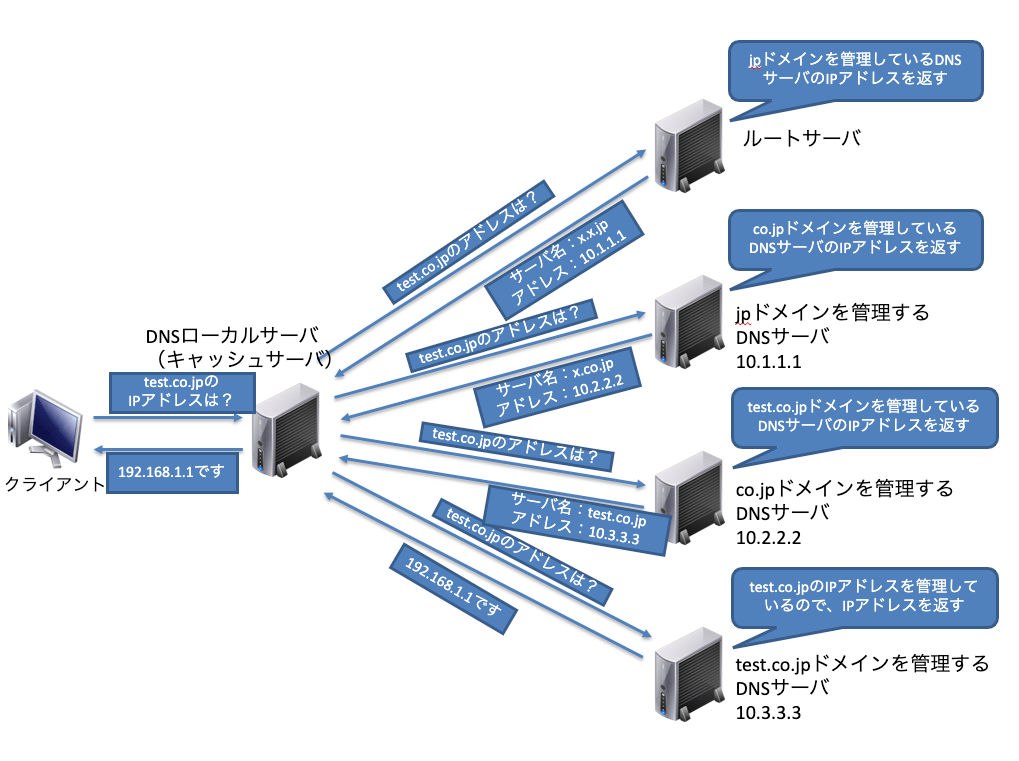
キャッシュを利用する
DNSサーバは分散処理されているため、目的のIPアドレスを調べるために複数のDNSサーバに聞いていかなければいけません。インターネットのように膨大なユーザーがひっきりなしにDNSサーバーへ問い合わせを行ってしまうと、当然DNSサーバーに負荷がかかってしまいます。
DNSではこの負荷を減らすために、キャッシュを保持しています。IPアドレスの問い合わせを行うローカル・サーバでは、DNSサーバへ問い合わせを行った内容を内部のキャッシュに保持して、次回問い合わせがあった場合、DNSサーバへ問い合わせを行う前に内部のキャッシュを調べます。キャッシュに情報があればその内容を使用し、なければDNSサーバへ問い合わせを行います。
hostsで名前解決
ここまでは、DNSでの名前解決の方法について説明しましたが、その他の名前解決の方法として、hostsファイルを使用した名前解決の仕組みがあります。hostsファイルはDNSが普及する前に行われていた仕組みで、クライアントPCにドメイン名とIPアドレスの対応表を記載したファイルのことです。
hostsファイルにドメイン名とIPアドレスの対応を記載すると、DNSよりも優先的に使用されます。
Windows 10の場合以下の場所にhostsファイルがあります。
C:\Windows\System32\drivers\etc\hostsMACの場合は以下の場所にあります。
/private/etc/hostsコマンドで名前解決をしてみる
クライアントPCからnslookupというコマンドを使うことで、名前解決を行うことが出来ます。Windowsであればコマンドプロンプトで、MacやLinuxであればターミナルから以下のコマンドを実行します。
nslookup [ドメイン名]
Windowsでの実行結果
C:¥>nslookup itbook.info
サーバー: ns1.example.com
Address: 192.168.1.1
権限のない回答:
名前: itbook.info
Addresses: 192.168.1.2「サーバー」と、その下の「Address」がIPアドレスを問い合わせた DNSサーバの名前とIPアドレスです。続く「名前」と「Address」が問い合わせたドメイン名とIPアドレスを表示しています。
「権限のない回答」と出力される場合は、DNSキャッシュサーバーがキャッシュしている内容を回答している事を示しています。
Pingは届くけどWebアクセスできない障害
ネットワークエンジニアとして仕事をしていると、WebサーバにPingは届くけどWebアクセスできないという障害に出くわすことがあります。
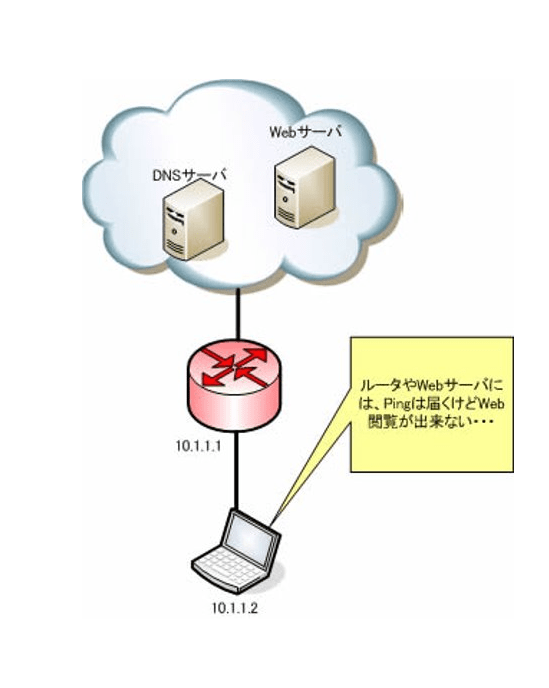
こんな症状の場合、Pingは通るということはIPレベルでの通信は確保できています。問題はネットワーク層よりも上のレイヤーで問題が発生している可能性があります。
特に今回の場合はDNSによる名前解決が正常に行われていない可能性が高いようです。そのような場合は、今回説明した「nslookup」コマンドを使ってトラブルシュートを行うと効率的です。
もし以下のようにエラーが出た場合、DNSの設定が間違っているか、DNSが動作していないことになります。
C:¥>nslookup itbook.info
サーバー: ns1.example.com
Address: 192.168.1.1
*** ns1.example.com が itbook.info を見つけられません: Non-existent domainPingはネットワーク層、つまりIPレベルで通信が可能であるかどうかしか分かりません。そのためPingでは、そのホスト上でDNSサービスが動作しているかどうかまでは分かりません。nslookupコマンドはDNSサービスと直接やり取りをすることで、動作状況や設定の確認をすることができます。このようにOSI参照モデルを頭に浮かべながらトラブルシューティングを行うことで、早く問題に辿り着くことができます。
POP、SMTP、IMAP
電子メールの送受信は、POP、SMTP、IMAPといった複数のプロトコルを組み合わせて行います。メールの送信時にはSMTP(Simple Mail Transfer Protocol)、受信時にはPOP(Post Office Protocol )やIMAP(Interactive Mail Access Protocol)が利用され、名前解決にDNSを利用しています。
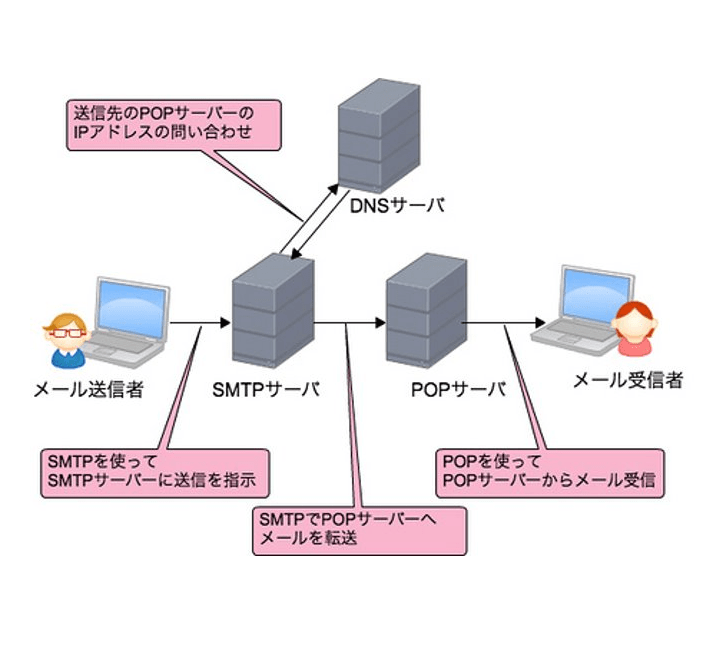
メールを書いてメール・ソフトの送信ボタンを押すと、メール・ソフトがSMTPを使用して内容を「メール・サーバ」へと送ります。メール・サーバでは、メールの宛先を見て、そのメールアドレスを管理するメール・サーバのIPアドレスを、DNSを利用して検索し、該当するIPアドレスへメールを転送します。宛先のメールサーバに届くと、宛先ごとのメール・ボックスに保存されます。
メールの受信者は、メール・ソフトがPOP3を利用してメールをチェックし、新着メールがあれば受信します。メールを転送する時には、宛先のメールアドレスを管理するメールサーバへメールを転送します。そのときに宛先メール・サーバのIPアドレスを調べるためにDNSを使用します。メールアドレスの「@以下」のIPアドレスを調べます。以上がメール配信の基本動作です。
SMTPのメール配送の仕組み
SMTPはメール・ソフトからメール・サーバへメールを送信する時と、メール・サーバ間でメールを転送する時に使用されます。メール・ソフトとメール・サーバ間のSMTPのやり取りは以下の通りです。
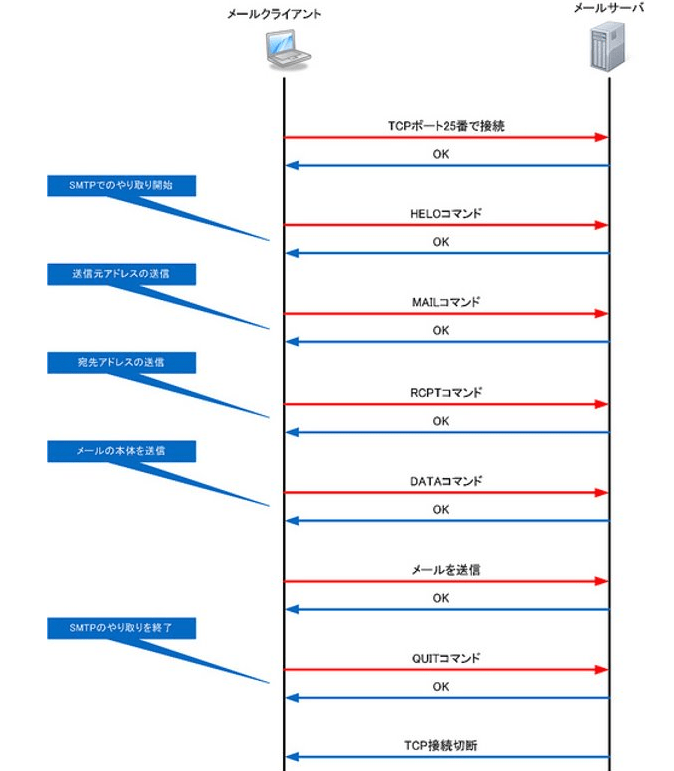
SMTPのやり取り自体は多いですが、やっていることはとってもシンプルです。まず、メール・ソフトからメール・サーバへTCPの25番ポート宛に「HELOコマンド」を送ります。メールサーバから「OK」が返信されてきたら、メールの送信元アドレス、宛先アドレス、本文の順番で送信します。メール・サーバからの返信メッセージには3桁の数字が含まれていて、この数字(コード)によってOKやエラーの種類を判断します。例えばコード「250」が返ってくればOKを意味して、「530」が返ってくればアクセス拒否を意味します。それぞれのコード番号と意味については以下の通りです。
| コード | 意味 |
|---|---|
| 200 | 正しくない応答コード(正しくは250)で、SMTPが標準化された初期に使われていた |
| 211 | システムの状態、またはシステムヘルプの応答 |
| 214 | ヘルプメッセージ |
| 220 | SMTPコネクションが確立したときに使われる |
| 221 | 転送チャンネルを閉じる(QUITに対する応答) |
| 250 | 要求されたコマンドが正常に終了したことを表す |
| 251 | 宛先として指定されたユーザはローカルに存在しないため、指定した宛先へ転送する |
| 252 | ユーザ確認ができず、メールの転送は可能 |
| 253 | サーバがそのノード宛メッセージをもっている際の成功コード(メッセージがない場合は251を使用する) |
| 334 | ダイジェスト待ち |
| 354 | DATAに対する応答。「.」が来るまでのすべてのデータをメール本文として扱う |
| 421 | サービスが利用不可能のため転送を閉じる |
| 432 | 認証メカニズムを変更する必要があることを示す |
| 450 | 他に該当しない一時的なエラー |
| 451 | データ処理中のエラー |
| 452 | システムのディスク容量不足 |
| 453 | メールが存在しない |
| 454 | サーバ側の原因により認証が失敗した |
| 458 | 何らかの理由でキューができない |
| 459 | 何らかの理由でそのクライアントにサービスが提供されない |
| 500 | 一般的な構文エラー、コマンドが解釈不能 |
| 501 | パラメータや引数の構文エラー |
| 502 | コマンドが実装されていない |
| 503 | コマンドの順序が正しくない |
| 504 | コマンドのパラメータが実装されていない |
| 521 | メールを受けとらない |
| 530 | 何らかの理由でアクセスが拒否された |
| 534 | 認証メカニズムが弱いことを示す |
| 535 | 認証エラー |
| 538 | 要求された認証メカニズムには暗号化が必要 |
| 550 | 要求されたアクションを実行できない |
| 551 | ユーザはローカルでない |
| 552 | 要求されたコマンドが中止された |
| 553 | 要求されたコマンドが受け入れられない |
| 554 | トランザクションの失敗 |
| 555 | MAIL/RCPTコマンドに対するパラメータエラー |
最後に「QUITコマンド」で送信終了をメール・サーバに知らせます。メール・サーバからOKコマンドが帰ってきたらTCPを切断して終了です。複数のメールを送信する場合は、この動作を繰り返していきます。SMTPで使用するコマンドには以下のようなものがあります。
| コマンド | 意味 |
|---|---|
| HELO | SMTPクライアントをSMTPサーバに認識させる |
| メール転送を開始。メールの送信元アドレスを指定 | |
| RCPT | メールの受信元アドレスを指定 |
| DATA | メッセージデータを送る |
| VRFY | ユーザ名の確認を行し、指定したユーザが存在すればユーザ情報を返す |
| EXPN | メーリングリストの会員アドレスの要求 |
| QUIT | セッションを終了させる |
| HELP | SMTPコマンドのhelpを要求する |
| NOOP | 操作なし(ダミーコマンド) |
| RSET | セッションの状態をリセット(メール転送処理の中止) |
| SEND | メール転送を開始。メールの送信元アドレスを指定 |
| SOML | メッセージをターミナルに出力 |
| SAML | メッセージをメールボックスとターミナルへ出力 |
| TURN | クライアントとサーバの役割の交換 |
複数の宛先にメールを送信する場合は、RCPTコマンドでメールの宛先を送信するときに、複数の宛先をまとめて送信します(5つの宛先を指定した場合は、RCPTコマンドを5回繰り返す)。
POPでのメール受信の仕組み
POP3はメールを受信するときに使用するプロトコルです。現在主流のバージョンは、POP Version3(POP3)のため、POP3という言い方が一般的になっています。POP3のやり取りは、大きく以下の3段階からなります。
- 認証
- トランザクション
- アップデート
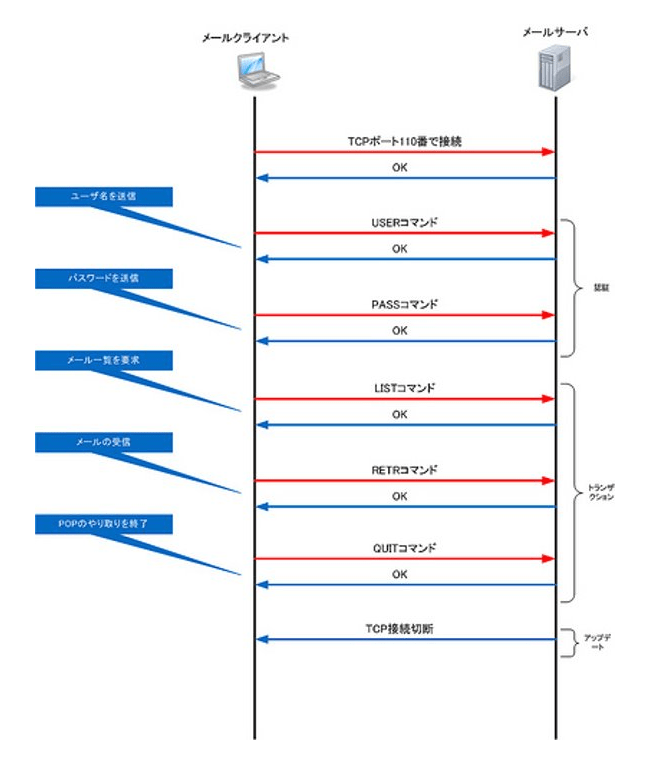
まず、メール・ソフトからメール・サーバへTCPの110番ポート宛に接続して「認証」を行います。認証段階では、アクセスしてきたユーザ名とパスワードをメール・サーバがチェックします。この時、メール・ソフトからUSERコマンドとPASSコマンドで「ユーザ名」と「パスワード」を送信します。認証が完了すると、「トランザクション」段階に移行します。ここでは、メール一覧を表示したり、メールを受信したりといった動作を行います。最後の「アップデート」段階では、メール・ソフトから依頼のあった処理をメール・サーバ側で処理する段階です。以上でPOP3による受信動作は終了です。
POP3で使用するコマンドには以下のようなものがあります。
認証で使用するコマンド
| USER | 認証するユーザー名を指定する |
| PASS | 認証するユーザーのパスワードを指定する |
| APOP | USER、PASSコマンドの認証の代わりに使用する。 |
| AUTH | IMAP4認証を行う |
| QUIT | ログアウトする |
トランザクションで使用するコマンド
| STAT | メールメッセージの数とサイズの問い合わせ |
| LIST | [メッセージ番号] メールメッセージ番号とそれぞれのサイズの問い合わせ。 |
| RETR | 指定されたメッセージ番号のメッセージ全体のダウンロード要求 |
| DELE | 指定されたメッセージ番号のメッセージの削除要求 |
| NOOP | 何もしない |
| RSET | 認証確立後発生した削除処理を全て取り消す |
| TOP | メッセージ番号 Line数 指定されたメッセージ番号のメッセージの指定されたLine分だけを表示する。 |
| UIDL | [メッセージ番号] メッセージunique-idの問い合わせ |
| QUIT | ログアウトする |
メール・サーバに届いた新着メールを見分けるには、メールごとに付与されているUID(Unique Identifier)をチェックします。メール・クライアントは、UIDLコマンドでメール・サーバにUIDリストを要求し、既に受信したメールのUIDと比較して、受信していないメールだけどメール・サーバから取り出す処理を行っています。
また、メールを取り込むプロトコルには、POPの他にIMAP4(Internet Message Access Protocol 4)というプロトコルがあります。POP3では基本的にすべてのメールをダウンロードしますが、IMAP4は指定したメールや添付ファイルだけどダウンロードすることができます。さらにメールをサーバ側に残したままで、既読や未読の管理が可能と、POP3よりも使い勝手が良いプロトコルです。
迷惑メールを防ぐ認証技術
メールを使っていると、迷惑メールを受信することがあります。迷惑メールが大量にくる理由として、メールを配送するプロトコル「SMTP」に認証するしくみが無いためです。POP3にはユーザを認証するしくみがあるのですが、SMTPにはそのしくみがないため、このしくみを悪用して大量の迷惑メールを送りつける被害が広がっています。
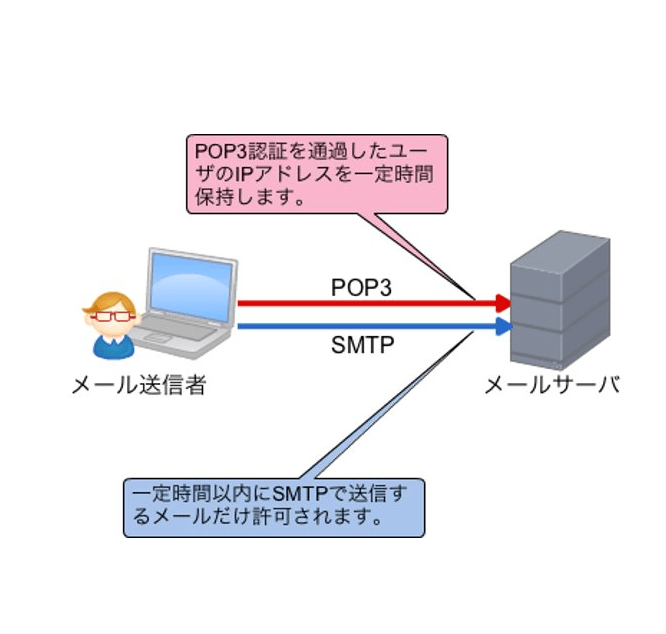
これではさすがにまずいということで考えられた技術が、「POP before SMTP」と「SMTP AUTH」という2つの技術です。「POP before SMTP」は、SMTPを使用する前にPOP3を使うというものです。POP3には認証するしくみがあるため、POP3で認証を行ってから、SMTPを使った通信を行います。POP3で認証すると、メール・サーバに認証したIPアドレスが一定時間保持されます。その時間内にSMTPの接続要求があったときだけ、接続を許可します。このような動作をするため、メールの利用者はメール送信前に必ずPOP3でメール・サーバにアクセスする必要がある点には注意が必要になります。
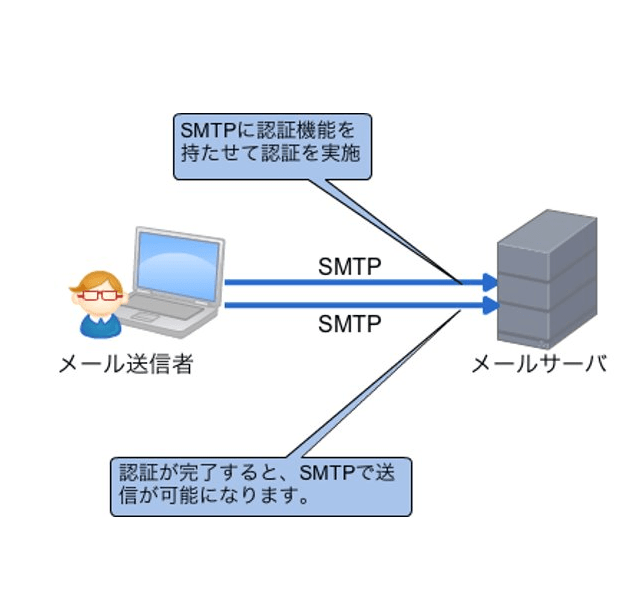
「SMTP AUTH」はSMTP自体に認証のしくみを入れたものです。「POP before SMTP」はメール・サーバ側にだけ設定を追加すれば良いのですが、「SMTP AUTH」は、メール・サーバ、メール・クライアントの両方で対応している必要があります。
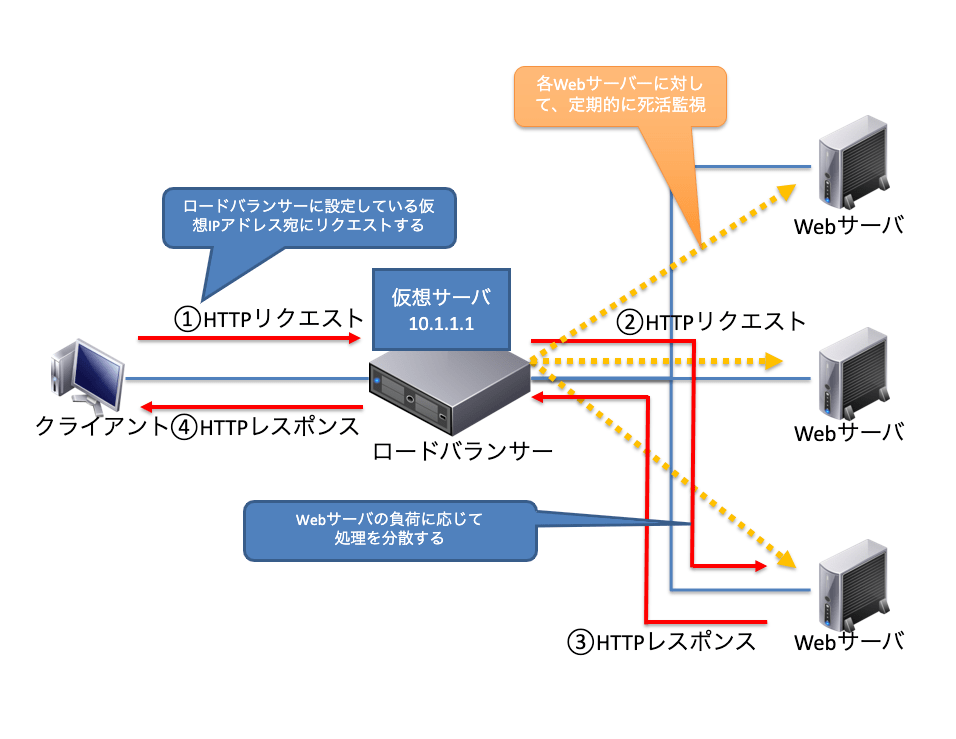
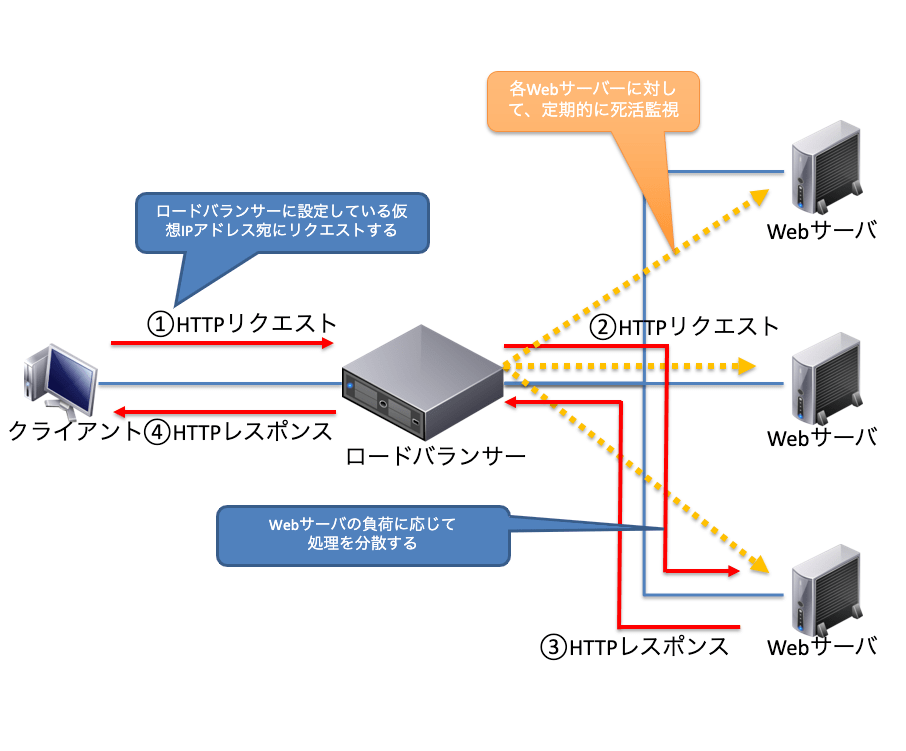
アプリケーション層で動作する機器
アプリケーション層で動作する機器には、ロードバランサーがあります。ロードバランサーは、サーバーにかかる負荷を分散するための装置です。大規模なWebサーバーを公開している企業だどでは、ロードバランサーをサイト全体の窓口に設置し、不特定多数のユーザーからのアクセスを複数のWebサーバーに分散させて処理させます。
また、ロードバランサーには、負荷分散に加えてサービスの可用性維持という機能もあります。ロードバランサーから各Webサーバーに対して、定期的に死活監視を行い、各サーバーが応答可能かどうかを常時チェックしています。故障などでサーバーが利用できない場合は、そのサーバーをリクエストの分散対象から外します。死活監視方法はPingレベルのものから、Webサーバー上で動作するサービスが正常に応答するかどうかを確認するアプリケーションレベルの死活監視まで可能です。
サーバーの負荷分散方式
サーバーの負荷分散方式にはさまざまな手法がありますが、基本的な分散方式は以下の2つの方式です。
・ラウンドロビン方式
・最小コネクション方式
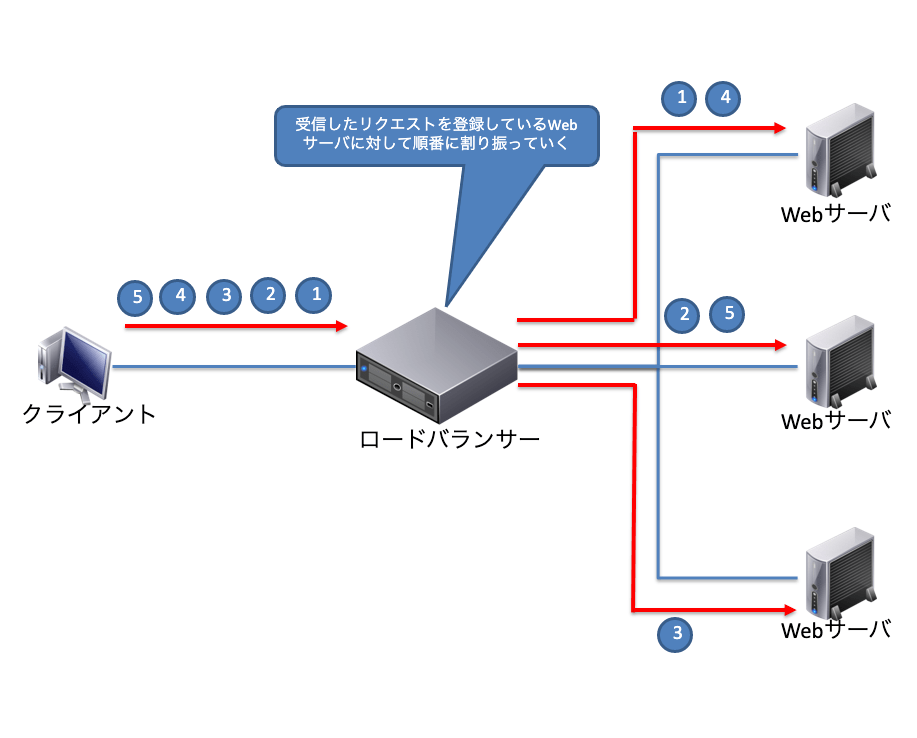
ラウンドロビン方式
ユーザーからのアクセスに対して、ロードバランサーは順番に登録しているWebサーバーに割り振る方式です。負荷分散の動作は単純ですが、すべてのWebサーバーに均等にアクセスを割り振るため、Webサーバーごとに負荷がばらつく可能性があります。
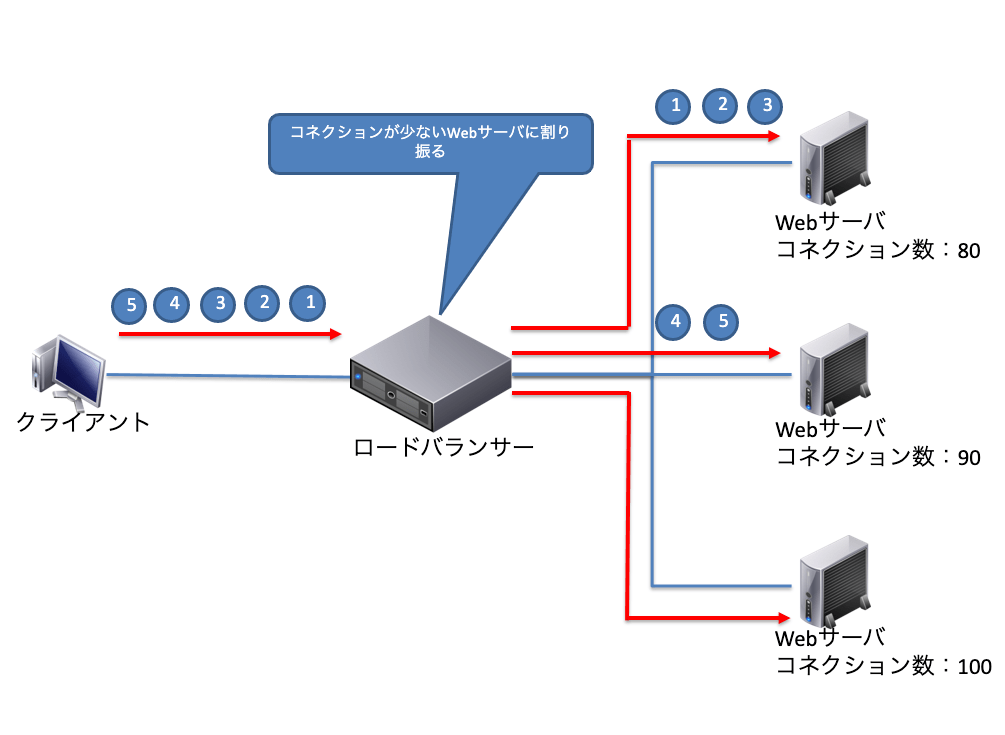
最小コネクション方式
ユーザーからのアクセスに対して、ロードバランサーは登録しているWebサーバーの中で最もコネクション数が少ないサーバーに割り振る方式です。基本的にWebサーバーの負荷はコネクション数に比例するため、コネクション数を均等にすることで、均等な負荷分散を実現する方式です。
セッション管理やコネクション管理の設計は慎重に
アプリケーション層にありがちなトラブルとして、ロードバランサー上のセッション管理とコネクション管理があります。ロードバランサーを導入する目的は、サーバーの処理能力の平滑化と、可用性の維持の2つがあります。ただし、単純にロードバランサーを導入すればよいわけではなく、事前の詳細な設計が必要です。設計を失敗すると思いがけないトラブルに出くわすこともあります。ここではアプリケーション層でありがちなトラブル事例をいくつかご紹介します。
サーバーの性能設計は障害時を想定しよう
通常時はロードバランサーにWebサーバーを2台登録して、ラウンドロビン方式で負荷分散を行っていたとします。
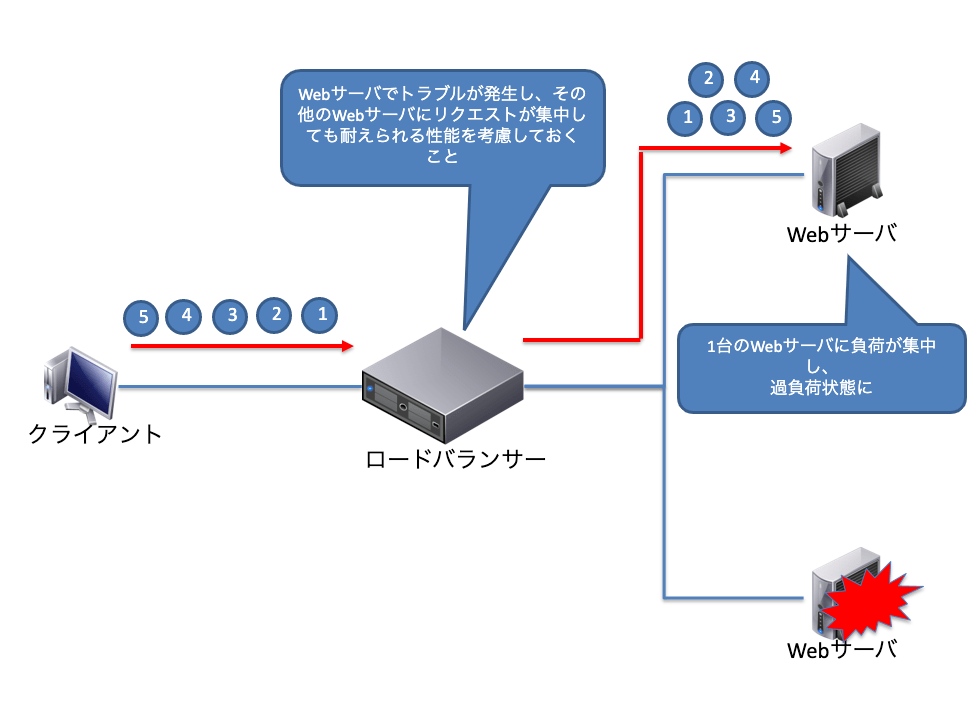
この構成で1台のWebサーバーが故障でダウンした場合、ロードバランサーはWebサーバーの故障を検出し、障害が発生したWebサーバーを切り離す動作を行います。その後はすべてのアクセスは正常のWebサーバーに集中することになります。そのため複数台のWebサーバーで負荷分散していたとしても、トラブルを想定して1台のWebサーバーに負荷が集中したとしても耐えられる性能を考慮しておくことが重要です。
コネクション管理設計は慎重に
ロードバランサーはアプリケーション層までの情報を基にトラフィックを制御します。具体的にはTCPやUDPのヘッダーやセッションシーケンス番号、データ部の情報などを解析し、場合によっては書き換えを行ってトラフィックを分散させます。そのためロードバランサー内部にはTCP/UDPのコネクションテーブルを持ち、コネクション情報を管理しています。
そのためロードバランサーの運用には、コネクション管理が重要になります。コネクション管理を意識せずに設計を行うと、通信断が発生したり、設計通りの負荷分散ができないなどのトラブルが発生してしまいます。
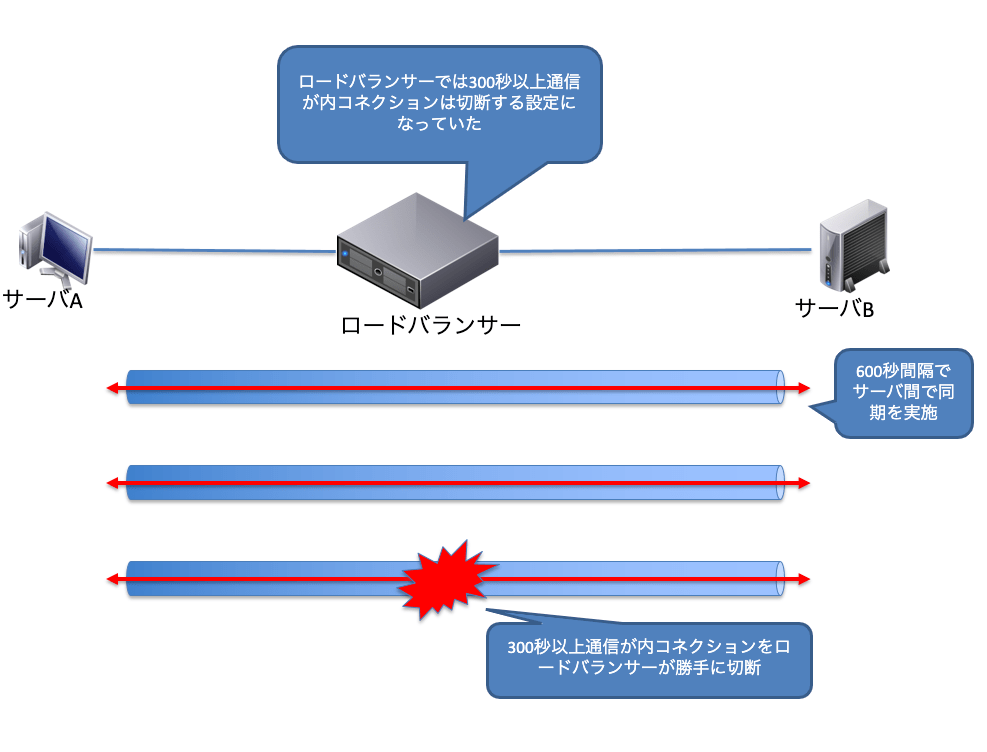
例えば、通常コネクション情報は一定時間通信が無いと削除されます。これは無駄なメモリー消費を防ぐための機能で、ロードバランサー内のコネクション情報はもちろん、サーバー内でも同様にコネクション情報を保持していて、一定時間通信が無いと削除されます。このコネクション情報の保持時間がロードバランサーとサーバーで異なっていた場合、タイミングによっては通信断が発生してしまいます。
現場でよくある7つの失敗
ネットワークエンジニアとして現場作業をしていて、作業ミスは絶対にしてはいけないのですが、どれだけ注意して作業をしていてもミスは無くなりません。しかしこういった失敗は、注意しておけば避けることができるものです。ここでは「現場でよくある7つの失敗」をご紹介します。
深く考えずに設定を変更する
遠隔地にあるルータにTelnet接続して、深く考えずに設定変更した後に、ルータに接続できなくなったなんて経験ないですか?残念ながら私は何度か遭遇したことがあります。特に運用している機器への設定変更は、事前の入念なチェックはもちろんのこと、当日の設定ミスを起こさない仕組み作り(二人で確認したり、ツールを使って設定するなど)が重要です。
ログを取得せずに設定を変更する
機器の設定を変更する前に、現状の状態を取得しておくことは、リスク管理の上でもとても重要です。現状の設定はもちろんのこと、現状の状態を確認しておくことで、設定変更で思わぬトラブルに陥ったときに切り分けを実施する際に役立ちます。また、設定作業中もログを取得しながら作業する癖をつけておきましょう。Teratermなどのターミナルソフトには、ログを取得しながら操作する機能がついていますのでぜひ活用しよう。
機器設定後の保存を忘れる
CiscoのIOSは、設定変更後に設定を保存しなければ、機器が再起動した場合に以前の設定に戻ってしまいます。設定作業が終わったら必ず、設定を保存する癖をつけておきましょう。
顧客の許可なく作業を行う
どんなに小さな作業であっても、顧客の許可なく作業することは許されません。もし、許可なく行った作業によってトラブルが発生した場合、あなた個人だけではなく、あなたの会社として顧客を失う危険性もあるので要注意です。
顧客の環境で検証してしまう
顧客での作業中に、「そういえば、このタイマーを変更すれば経路の収束が早くなるんだっけ。ちょっと変更してみるか」などと、顧客の環境を使って検証するのは絶対にやめておきましょう。そのようなことは検証環境を使ってやるべきで、顧客の環境でやるべきではありません。顧客があなたの会社にお金を払っているのは、あなたのスキルを上げるためではなく、顧客の問題を解決するためであることを忘れてはいけません。
状況を把握せずに障害切り分けを開始する
顧客のネットワークで障害が発生し、あなたが現場に駆けつけてまずやることは、状況を把握することです。いきなり障害切り分けを実施しようとするエンジニアは決してプロフェッショナルとは呼べません。まず「障害の内容」、「現在の状況」を把握し、現在のネットワーク構成から考えられる問題点を洗い出してから障害切り分けに取り組むべきです。
最終的な確認をすることなく作業を終了してしまう
エンジニアとしてのあなたの視点からは、作業が全て完了したかのように見えているかもしれません。だからといってそこで作業を終了して退室してしまうのは大きな間違いです。最終的な作業の終了は、顧客の視点から見ても想定通りの動作をしていることです。実際に使うのはエンジニアではなく顧客であることを忘れてはいけません。顧客にコンピュータ等を操作してもらい、最終的な動作の確認をしてもらいましょう。
関連記事
検索
特集


著書




おすすめ記事