トランスポート層の仕事
トランスポート層の役割は、ネットワーク層でノード間の通信を行う機能を提供した後に、ノード間で通信を行うアプリケーション間でエラーの無い通信路を提供することが役目です。ネットワーク層では、ノード間通信の機能は提供しているものの、そこでやり取りされるデータが実際に相手にちゃんと届いているのかどうかを確認する事は出来ません。トランスポート層では、ちゃんと相手にデータが届いているか、エラーが発生していないかを管理してくれます。これらの仕事をするプロトコルが「TCP」と「UDP」です。トランスポート層のプロトコルはこの2つのプロトコルの動作を押さえておけば問題ありません。
またインターネット上にはメールやSMS、Web閲覧など様々なトラフィックが流れますが、混信することはありません。それはトランスポート層でパケットごとに仕分けされて適切なアプリケーション層へと渡しているためです。この仕分けの役目をしているので「ポート番号」です。
トランスポート層ではポート番号が活躍
ネットワーク層は、ノード間の通信を行う機能を提供するために、IPアドレスを使用しています。IPアドレスはネットワークアドレスとホストアドレスに分かれていて、どのネットワークのどのノードにパケットを転送すればよいかが分かるようになっています。しかし、どのアプリケーションにデータを渡すのかはIPアドレスでは知る事が出来ません。そこでトランスポート層では、「ポート番号」を使用してどのアプリケーションに渡すべきなのかを判断しています。
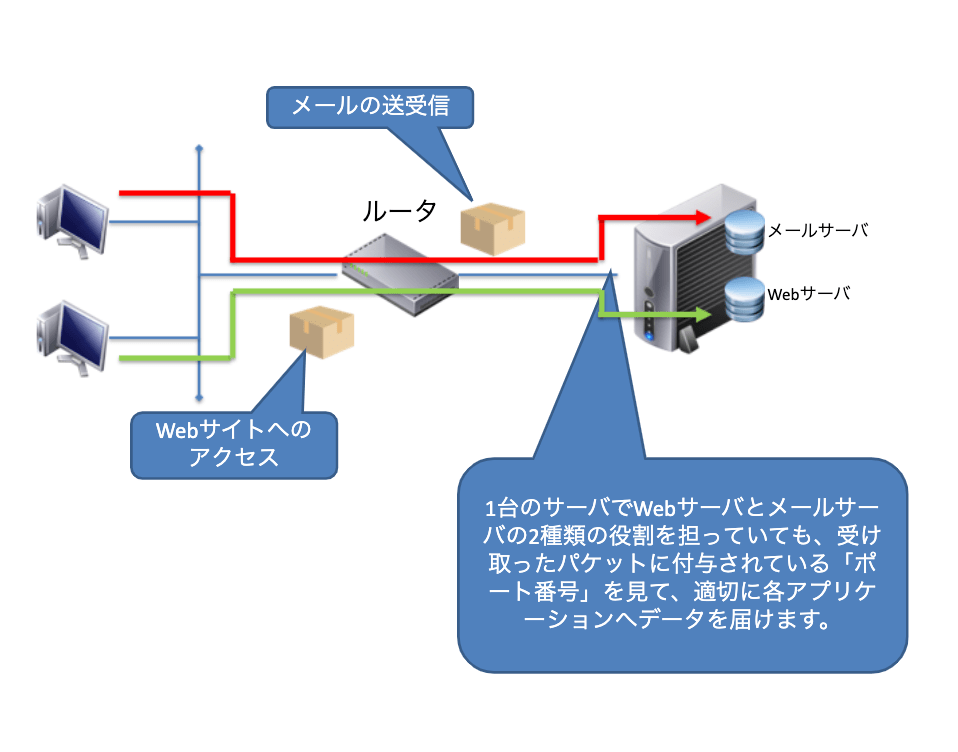
当然、「ポート番号」を見てどのアプリケーションなのかを判断するわけですから、ポート番号は「一意の番号」でなければいけません。ポート番号は16ビットの2進数で表され、0~65535の範囲で割り振られます。IPアドレスはインターネット上で一意でなければいけませんでしたが、ポート番号は各サーバで一意であれば問題ありません。
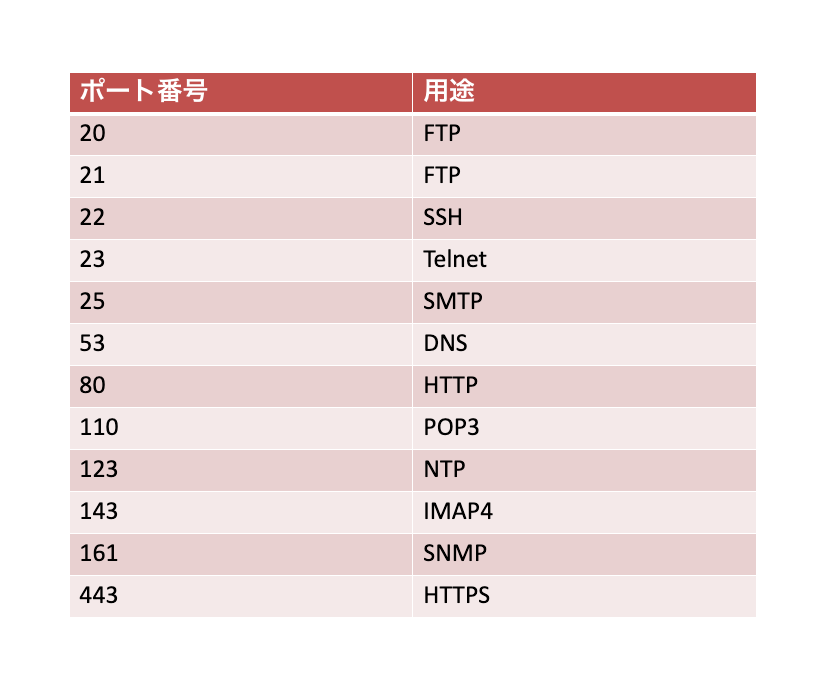
例えば、「SV–1上ではポート番号80がWebへのアクセス」で、「SV–2上ではポート番号8080がWebへのアクセス」だったとしても問題ありません。しかし、ポート番号は各サーバごとに一意で良いのであれば、世界中のサーバでサービスごとのポート番号が違ってしまうことも考えられます。そこで主要なサービスについてはあらかじめポート番号をめておこうということになりました。たとえばWebサービスはポート番号80、メール転送サービスはポート番号25、DNSはポート番号53というように主要なサービスについては標準化されました。このあらかじめ決められているポート番号のことを「ウェルノンポート」といいます。ウェルノンポートはポート番号1~1023までの範囲で決められています。
以下に「ウェルノンポート」の一例を挙げておきます。
ポート番号1024以降の番号はランダムポートと呼ばれていて、クライアント側が送信時に送信元ポート番号として使用します。このときクライアントは、送信を行う際に空いているポート番号からランダムに番号を使用します。
なぜ送信側にもポート番号が使用なのか?
データ通信の基本を考えれば簡単です。基本的にデータのやり取りは双方向で行われますから、サーバからクライアントへのデータのやり取りも行われます。サーバ側からクライアント側へデータを送り返す際に、クライアントのどのアプリケーションへ渡せば良いかが分からなくなってしまいます。そのためクライアント側でもポート番号が必要になります。
コネクションとコネクションレス
トランスポート層で動作する「TCP」と「UDP」は、アプリケーションとIPの仲介役という意味では同じですが、動作が大きく異なります。TCPとUDPの大きな違いはコネクション型かコネクションレス型かという点になります。
コネクション型とコネクションレス型
トランスポート層の役割は「アプリケーションレベルでの通信を確立する」ことで、そのためにポート番号を利用して制御をしています。TCPでもUDPでもそれぞれのヘッダにあて先、送信元のポート番号を付与していて、アプリケーションの制御を実施しています。コネクション型とコネクションレス型の違いは、このアプリケーションの制御方法の違いに関係してきます。
コネクション型
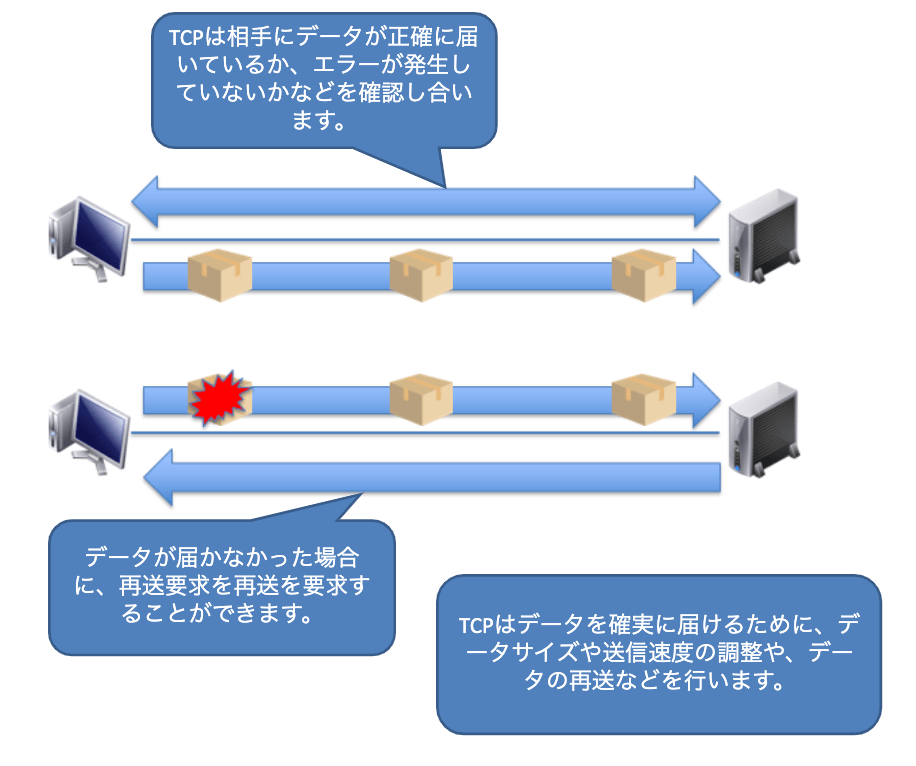
コネクション型はその名の通り、通信を確立するもの同士で連絡を取り合って制御を行う方式です。日常のやり取りで例えるならば電話がまさにコネクション型です。電話は互いに受話器を持って話をします。話をした言葉は相手にちゃんと届きますし、もし話している途中でうまく聞き取れないときには、相手に聞き返してもう一度同じ内容を聞く事も出来ます。このように、通信を確立するためにお互いが連絡を取り合って制御する方式をコネクション型と呼んでいて、信頼性がある方式であるといえます。コネクション型の代表的なプロトコルには「TCP」があります。
コネクションレス型
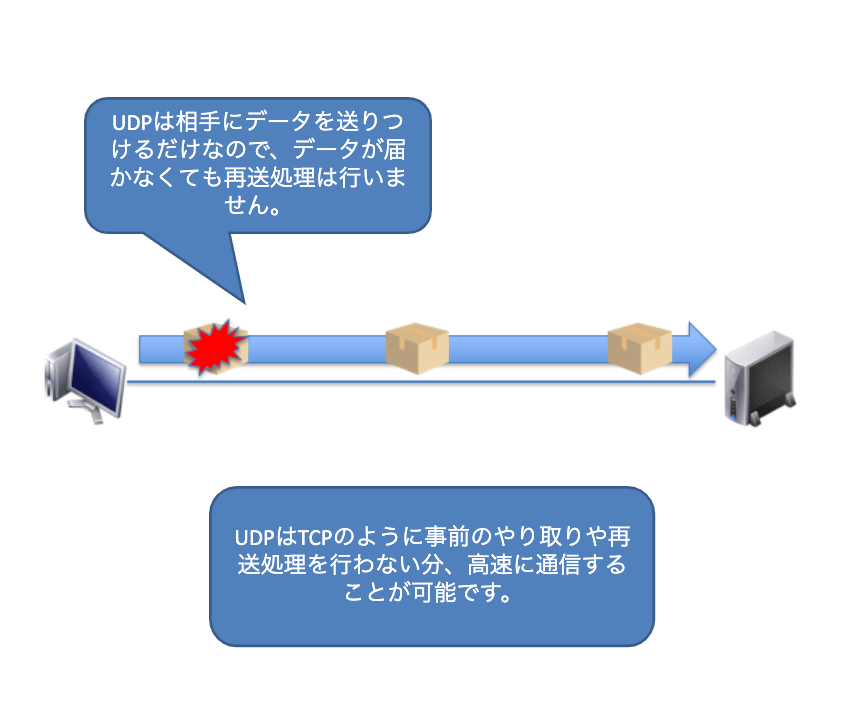
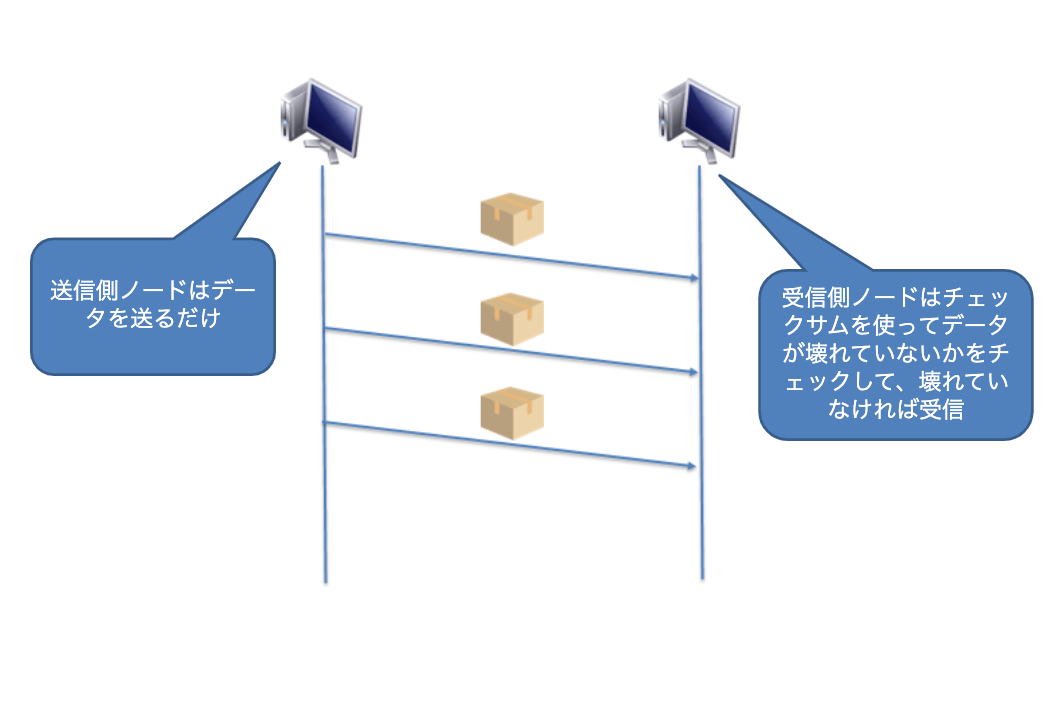
コネクションレス型は、連絡を取り合って制御はせずに、相手が受け取る準備ができているかにかかわらず、送信してしまう方式です。手紙のやり取りがまさにコネクションレス型です。相手が何をしていようと手紙を送りつけて、基本的にいつ届くのかはわかりませんし、もしかしたらどこかで紛失してしまい、相手に届かないこともあるかもしれません。このようにコネクションレス型は、相手が何をしているかは関係なしに送りつける方式です。
もちろん途中でパケットが消失してしまったり、到着順も考慮していません。そのためコネクションレス型通信は信頼性のない通信と言われています。
それぞれのメリットとデメリット
コネクション型はお互いが連絡を取り合う必要があることから、安定した通信を実現できることがメリットですが、確認のためのデータのやり取りが発生することから、ネットワークのトラフィックが増大してしまうというデメリットがあります。コネクションレス型はネットワークへの負荷が軽いため
通信の効率が良いメリットがありますが、相手に届いたかどうかを確認しないため信頼性が低いというデメリットがあります。
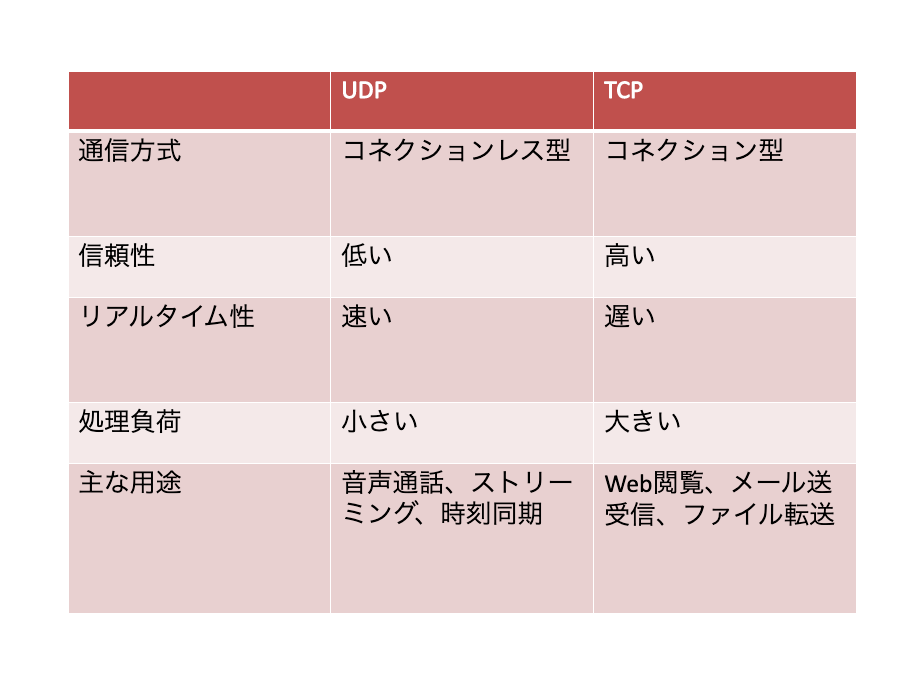
このようにコネクション型のTCPと、コネクションレス型のUDPにはそれぞれにメリット、デメリットが存在します。通信の目的に応じて信頼性を重視したいアプリケーションであれば、「TCP」を使用した方が良いですし、効率性を重視するのであれば「UDP」を使用したほうが効率的です。
UDP
UDPコネクションレス型のプロトコルです。コネクションレスなので、信頼性よりも効率性重視の仕様となっています。
UDPヘッダ
UDP のヘッダは以下のような構成となっています。
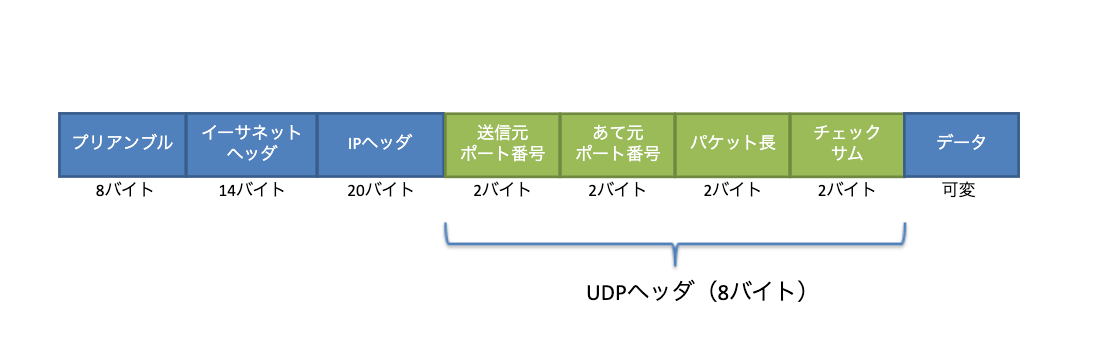
見て分かるように、効率性を重視しているため非常に単純な構造になっています。それぞれのフィールドの意味は以下の通りです。
- 送信元ポート番号:16 ビット
送信元ノードのアプリケーションが使用しているポート番号がセットされます。 - 宛先ポート番号:16 ビット
宛先アプリケーションが使用するポート番号がセットされます。 - パケット長:16 ビット
UDPヘッダの長さ(通常は64ビット)とデータ部分の長さを合計した数値がセットされます。 - チェックサム:16 ビット
通信中にエラーが発生していないかどうかをチェックする数式がセットされます。ここでいっているエラーとは、送られるパケット自体のエラーの有無で、相手とやり取りされる通信の確実性ではありません。
UDPの動作
UDPは効率よくデータを送信することを目的としていますので、「相手はデータを受け取る準備が出来ているのか?」、「相手に間違いなくデータが届いているのか?」といったことは一切無視して、データを相手に送りつけます。もちろん相手がしっかり受け取ったかどうかはまったく気にもしません。そのため、UDP ヘッダには相手と自分のポート番号ぐらいしか
フィールドも存在しません。
UDPヘッダのサイズは8バイト
次に説明するTCPのヘッダサイズは標準でも20バイトですので、いかにUDPには余計なヘッダが付いていないかが理解できると思います。このことからも、UDPの通信効率は非常に良いことが分かります。
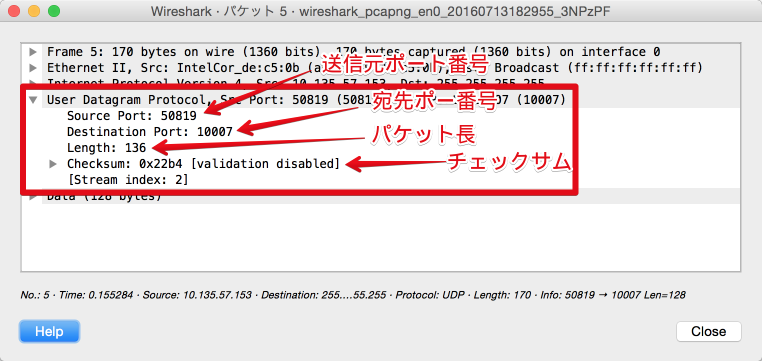
UDPパケットをキャプチャした結果が以下になります。
UDPを使用した代表的なプロトコル
UDPを使用した代表的なアプリケーションプロトコルには以下のようなものがあります。
- DHCP
IPアドレスやサブネットマスクなどを自動で設定するためのプロトコル。 - DNS
ドメイン名に対するIPアドレスを調べるためのプロトコル。TCPを使用することも可能。 - RIP
ルータ間でルーティングテーブルのやり取りをするためのプロトコル。
TCP
TCPコネクション型のプロトコルです。コネクション型ですから、効率性よりも信頼性重視の仕様となっています。
TCP ヘッダ
TCP のヘッダ構成は以下のようになっています。
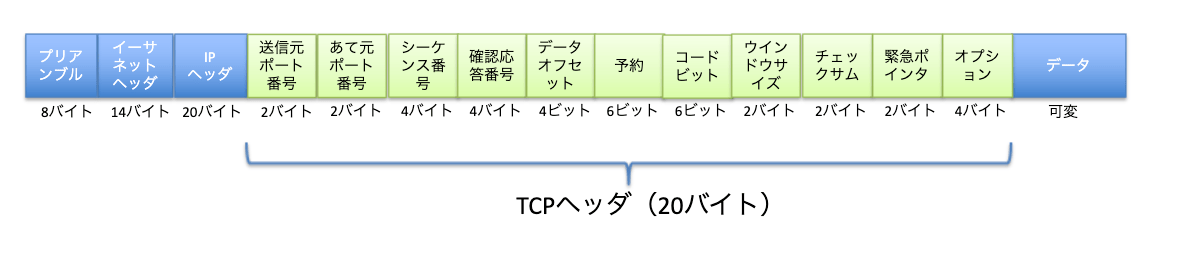
UDPのヘッダと比べても非常に多くのフィールドが存在していることが分かるかと思います。それぞれのフィールドの意味は以下の通りです。
- 送信元ポート番号:16 ビット
送信元ノードのアプリケーションが使用しているポート番号がセットされます。 - 宛先ポート番号:16 ビット
宛先アプリケーションが使用するポート番号がセットされます。 - シーケンス番号:32 ビット
送信するデータには、順序を付けるための「シーケンス番号」が付与されます。このシーケンス番号で、この「データはデータ全体の中のどの位置のデータなのか」が分かるようになります。シーケンス番号は送信元ノードで管理され、データを送信するたびにデータ1バイトごとにシーケンス番号が加算されていきます。 - 確認応答番号:32 ビット
このフィールドは、受信したデータに対してどのどの位置まで受信したかを表すためのフィールドで、次に受信するデータのシーケンス番号は付与されます。確認応答番号は受信側ノードが、送信元ノードへの応答パケットに付与して送信されます。 - データオフセット:4 ビット
TCPデータのヘッダ超が格納されるフィールドです。TCPヘッダの長さはオプションがない場合、20バイトとなるため、このフィールドには5(2 進数だと0101)がセットされます。 - 予約:6 ビット
このフィールドは将来の拡張のために用意されていて、通常はすべて「0」がセットされます。 - コードビット:6 ビット
コードビットは1ビットずつに役割があり、フラグとして使用されています。初期値はすべて「0」ですが、値が「1」の場合にそれぞれのフラグが有効となります。
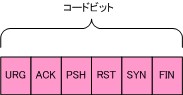
各ビットの役割は以下の通りです。
URG(Urgent フラグ) このフラグが「1」の場合に、パケットの中に緊急に処理しなければいけないデータが含まれていることを表しています。
ACK(Acknowledgement フラグ) このフラグが「1」の時は、TCPヘッダの中に確認応答番号フィールドが有効であることを表しています。通常はコネクションを確立するとくに最初に送信するTCPパケット以外は常に「1」がセットされています。
PSH(Push フラグ) このフラグが「1」の時は、受信したデータをすぐに上位のアプリケーションに渡すことを意味しています。通常TCPで送信されたデータは、受信側でバッファに溜めてから、適当なタイミングで上位アプリケーションに渡されます。この場合、応答性の高いアプリケーションの場合に、遅延が発生する可能性があるため、応答性を向上させたい場合にこのフラグを有効にします。
RST(Reset フラグ) このフラグが「1」の時は、TCPのコネクションが強制的に切断されます。何らかの理由で、TCPの接続が中断したままの場合などに、このフラグを有効にして強制的にTCP接続を終了させることができます。また、TCP の接続要求に対して、RST フラグを有効にして返信した場合、接続を拒否していることを表しています。
SYN(Synchronize フラグ) このフラグが「1」の時は、TCP の接続要求を表して居ます。TCPの接続を開始したい場合には、このフラグを有効にしてTCPパケットを送信します。
FIN(Fin フラグ) このフラグが「1」の時は、コネクションの切断要求であることを表しています。このフラグが有効になっている場合、これ以上データの受信の必要がないことを意味していて、FINフラグがセットされたパケットを送信側、受信側の双方で送信し、コネクションの切断を実施します。
ウインドウサイズ:16 ビット
受信側の受信可能なデータサイズを送信側に通知するために使用されます。送信側では、このフィールドにセットされたウインドウサイズを見て、送信可能な最大データサイズを判断します。チェックサム:16 ビット
UDPのチェックサムと同じで通信中にエラーが発生していないかどうかをチェックする数式がセットされます。緊急ポインタ:16 ビット
コードビットフィールドのURGフラグが有効になっているときに使用するフィールドです。このフィールドには、緊急に処理しなければいけない、データの場所を示す値がセットされます。オプション
TCP 通信で機能を付加する場合に使用されるフィールドです。
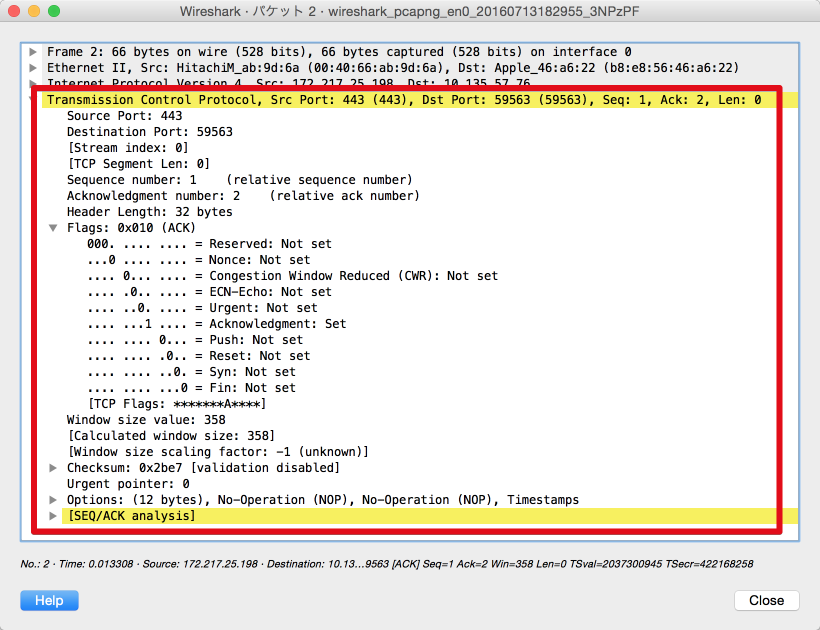
TCPパケットをキャプチャした結果が以下になります。
信頼性を高めるための3つの技術
TCPでは信頼性を向上させるために以下の3つの技術を採用しています。
- 相手が通信可能かどうかを確認する機能
仮想コネクションの確立 - 相手にパケットが届いたかどうかを確認する機能
ACKによる到達確認 - 相手の処理能力に合わせてデータサイズを調整する機能
ウインドウサイズを利用したフロー制御
仮想コネクションの確立
TCPは信頼性を高めるために、相手が通信可能かどうかを事前に確認し、通信可能であればデータのやり取りを行い、通信不可能であれば通信可能に成るまで待機するか、一定時間後に再送信を行う機能が備わっています。この機能の事を「仮想コネクションの確立」といいます。この「仮想コネクションの確立」を、「3ウェイハンドシェイク」と呼ばれる方法でノード間でやり取りされます。
3ウェイハンドシェイクはその名の通り、パケットのやり取りを3回行う事から呼ばれています。具体的なやり取りは以下の通りです。
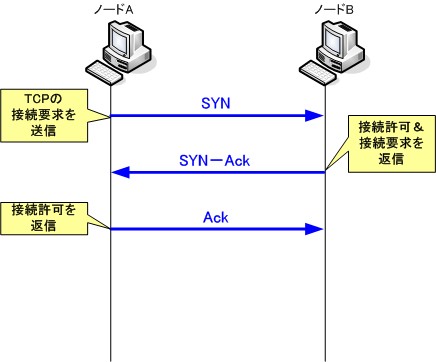
まず、送信側ノードから、接続要求のパケット(SYN)を受信側ノードへ送ります。SYNを受け取ったノードは接続可能であれば、接続許可(Ack)及び、接続要求のパケット(SYN)を組み合わせたパケットを返信します。受信側からも SYNパケットを送る理由は、TCPは双方向の通信のため、受信側からも仮想コネクションの確立をする必要があるためです。最後に、送信側からも接続許可パケット(Ack)を送り、仮想コネクションが確立されます。
TCPを使った接続は、必ずこの3ウェイハンドシェイクから始まります。実際の現場でもTCPの接続トラブルが発生した時に、3ウェイハンドシェイクが確実に完了しているかどうかを確認することもあると思いますので、しっかりと理解しておきましょう。
ACKによる到達確認
仮想コネクションが確立し、実際にデータのやり取りをしているときも、データの到達性を高めるために、そのデータが宛先にちゃんと届いているかどうかを常に確認しています。確認方法は、3ウェイハンドシェイクによるやり取りでも出てきた、Ackパケットを利用します。
受信側ノードは、送信側ノードからデータを受け取ると、Ackパケットを返します。送信側ノードはAckパケットを受信することで、データがちゃんと相手に届いた事を認識することが出来ます。
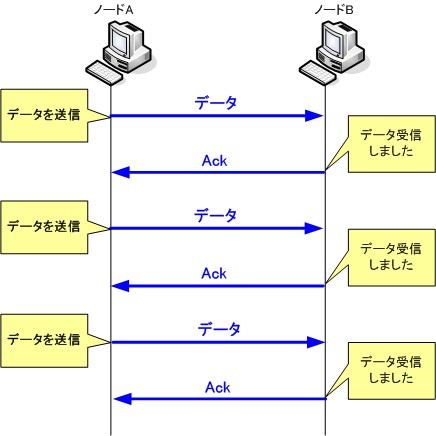
このように送信したデータごとにAckパケットを送信する事で、すべてのデータが送られることを確認する事ができます。
もしAckパケットが返ってこなかったらどうなるでしょう?TCPの動作では、データ送信後に一定時間経ってもAckパケットを受信出来なかった場合、同じデータをもう一度送信します。
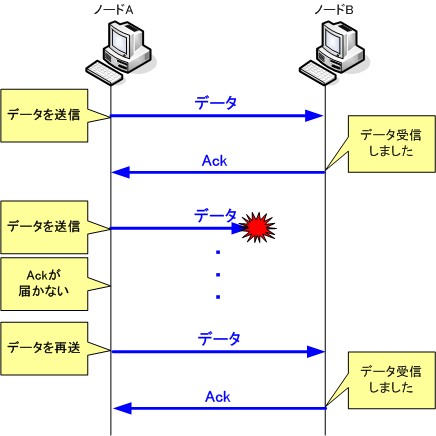
再送後にAckを受信すれば次のデータを送る動作に移るのですが、もしそれでもAckを受信出来ない場合は、再送が繰り返されます。あらかじめ決められた回数や時間が経過してもAckを受信出来ない場合は、TCPコネクションが切れたと判断し、上位のアプリケーションにエラー通知を行います。再送処理を何回まで行うか、どれぐらいの時間までガマンするかといった値は、プロトコルとして決まられているわけではなく、TCPの実装に依存しています。また、再送が繰り返される場合は、途中の経路が混雑している場合が考えられるため、再送を行うたびに再送する時間を増やしていきます。
ウインドウサイズを利用したフロー制御
以下のように送信側ノードがむやみにデータを送信した場合、受信側ノードのデータ処理能力が低く、すべてのデータを受信できない可能性が発生してしまいます。
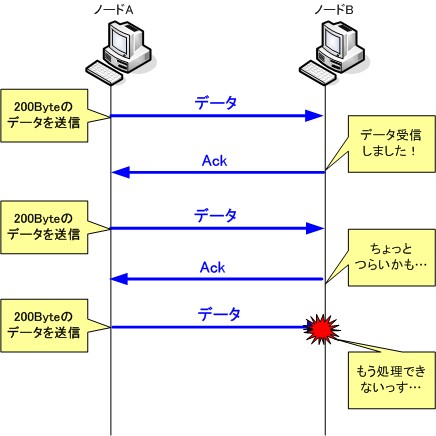
このような状態が続けば、当然通信の信頼性は落ちてしまいます。そのため受信側ノードの処理能力を考慮しつつ、最適なデータサイズを送信する機能が必要になります。この機能を「フロー制御」と呼びます。
送信するデータのサイズは、「ウィンドウサイズ」を使用して最適化を行っています。一度に受信できるデータのサイズを「ウインドウサイズ」と呼び、送信側ノードは受信側ノードから通知されるウインドウサイズに従って、送信するデータのサイズを調整しています。受信側ノードは、データを受信するたびに返信するACKパケットにウインドウサイズを盛り込んで通知しています。
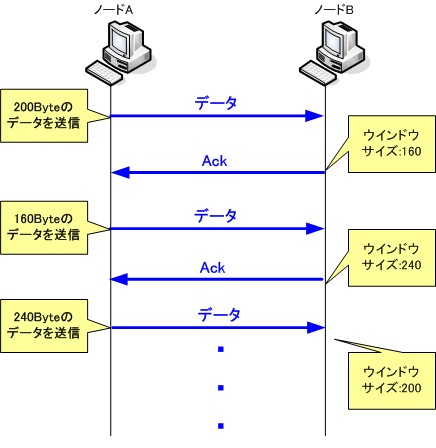
もし受信側で処理できなくなった場合は、ウインドウサイズを「0」にしてACKパケットを送信します。すると、送信側ノードはデータの送信を中断します。受信側ノードでデータ受信が出来る状態になると、改めてACKパケットを送信することで、データ送信が再開されます。
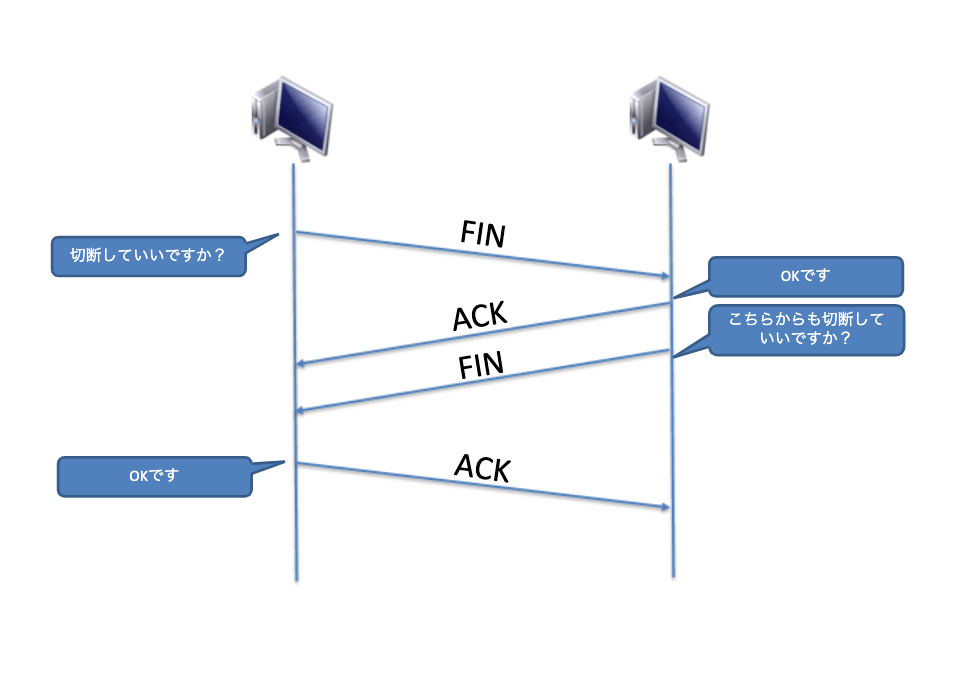
TCPはコネクションを確実に終わらせる
TCPはコネクション型ですので、アプリケーションの通信が終わったら確実にコネクションを終わらせることが必要です。コネクションを閉じるには「FINフラグ」を利用します。
FINフラグ
TCPヘッダーにある「FINフラグ」が「1」の時、コネクションの切断要求であることを表しています。このフラグが有効になっている場合、これ以上データの受信の必要がないことを意味していて、FINフラグがセットされたパケットを送信側、受信側の双方で送信し、コネクションの切断を実施します。
アドレス変換
インターネットのブロードバンド化が急激に進み、家庭でインターネットを利用することが当たり前になりました。通常、家庭や企業のネットワークにはプライベートアドレスが使われますが、そのままではグローバルアドレスが割り当てられているインターネット上のサーバーとは通信することができません。そのため、プライベートIPアドレスを使っていたとしてもインターネットに接続できるようにする技術を「アドレス変換」といいます。
「アドレス変換」とはパソコンから送信されたパケットの中からIPアドレス部分を見つけ出し、IPアドレスを付け替えてしまうという技術です。
2種類のアドレス変換機能
このアドレス変換機能には大きく分けて2種類あります。1つは単純にIPアドレスを変換(付け替える)方法で、これを「NAT(Network Address Port Translation)」と呼びます。2つ目は、IPアドレスの他にポート番号も変換(付け替える)方法で、これを「NAPT(Network Address Port Translation)」あるいは「IPマスカレード」と呼んでいます。
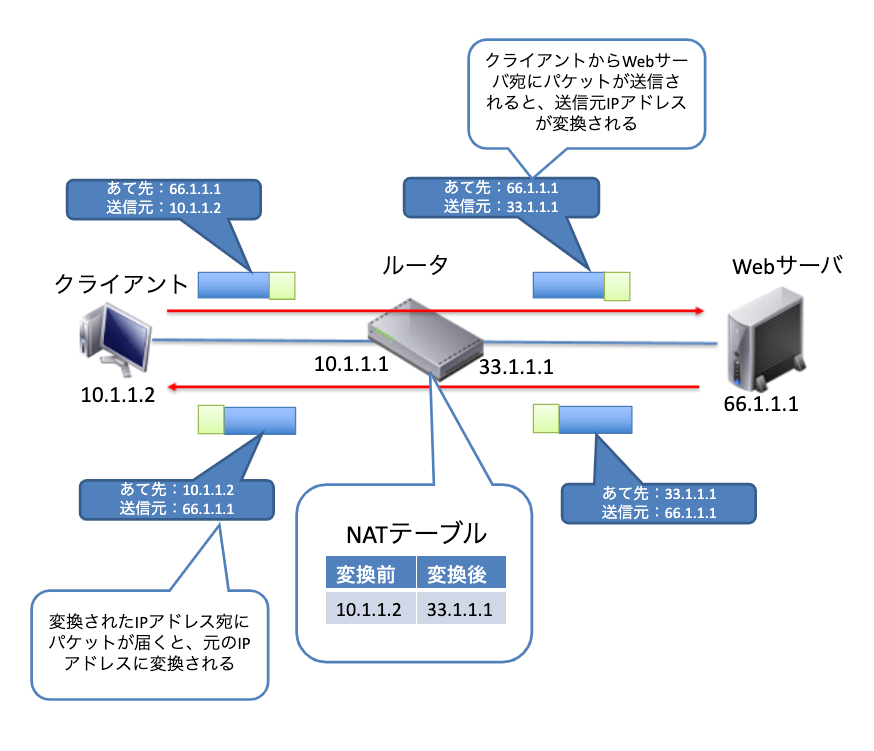
NAT(Network Address Port Translation)
上図の構成を見ると、LAN側のPCのアドレスは10.1.1.2が振られています。もし、このアドレスのままパケットをインターネットへと送信したとしても、すぐに破棄されてしまいます。そこでLANとインターネットの間にあるルータで、送信元IPアドレス(10.1.1.2)を、自身が保持しているグローバルIPアドレス(33.1.1.1)に置き換えてインターネットへパケットを送信します。このときの変換前と変換後のIPアドレスを自身のテーブルに記録しておきます。このテーブルのことをNATテーブル(あるいは変換テーブル)といいます。そのパケットが目的のサーバへと到達すると、そのパケットに対する返信をパケットの送信元IPアドレスである33.1.1.1に返信することになります。ルータへとパケットが到着すると、自身のNATテーブルを確認し、元の送信元IPアドレスである10.1.1.2に置き換えてLAN側へと送信します。この一連の動作によって無事にインターネット上のサーバと通信が可能になります。
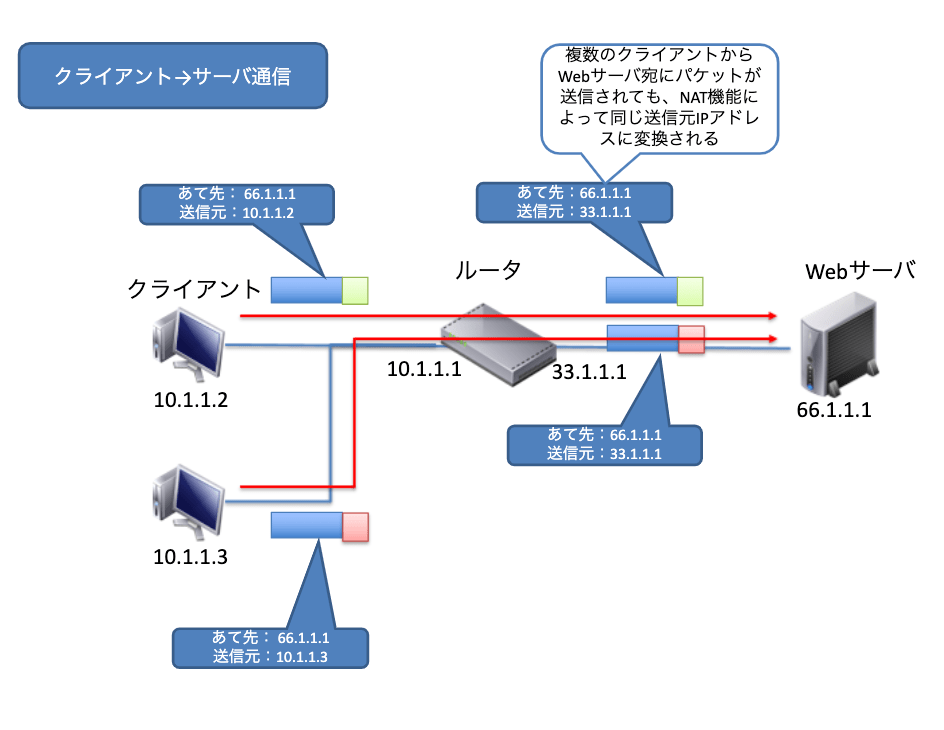
NATの問題点
NATには1つ大きな問題があります。それはルータが保持しているIPアドレスの数しか同時に接続が出来ないという事です。LAN側に接続されている複数のPCを1つのIPアドレスに変換して、インターネットにパケットを送信した場合、そのパケットの返信はすべてルータのIPアドレス宛に返ってきます。この時にルータはNATテーブルを見ても、どのPCのアドレスに置き換えればよいのかを判断することができません。
そんな問題を解決するために考え出されたのが、NAPT(IPマスカレード)という機能です。
NAPT(IPマスカレード)
NAPT(Network Address Port Translation)は、IPアドレスの変換に加えてポート番号も変換してしまうという機能です。通常IPパケットには、IPアドレスに加えて送信元と宛先のポート番号も記述されています。その送信元のポート番号を置き換えることで複数のPCが同時にインターネットへ通信できるようにしています。
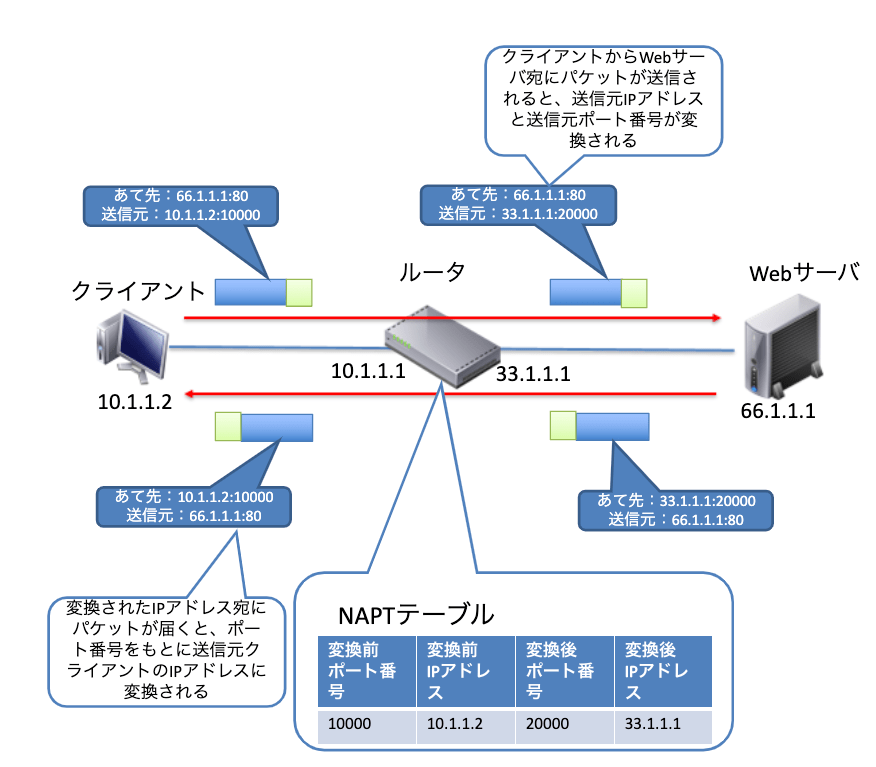
LANに接続されているPCがインターネットへパケットを送信すると、ルータは自身が保持しているグローバルIPアドレスに変換するのに加えて、送信元ポート番号も書き換えます。この時変換前と変換後のIPアドレスとポート番号を自身の変換テーブルに記録しておきます。
パケットが目的のサーバに到達し、その応答パケットがルータのグローバルIPアドレスへと返されます。返信されたパケットの宛先ポート番号と自身の変換テーブルをチェックして、どのPC宛のパケットなのかを判断し、その宛先のIPアドレスに変換してLAN側へ送信します。
このようにIPアドレスとポート番号を管理することで、同時に複数台のPCの通信が可能になります。
アドレス変換の弊害
アドレス変換を使用することでアプリケーションやネットワーク構成によっては弊害が発生します。
インターネットからLANへの通信
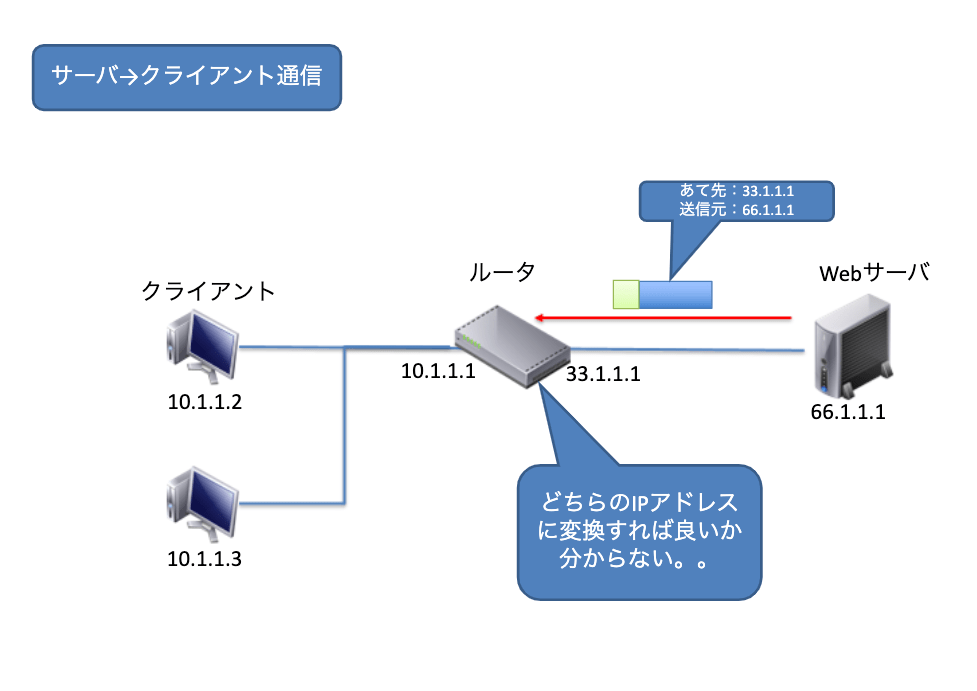
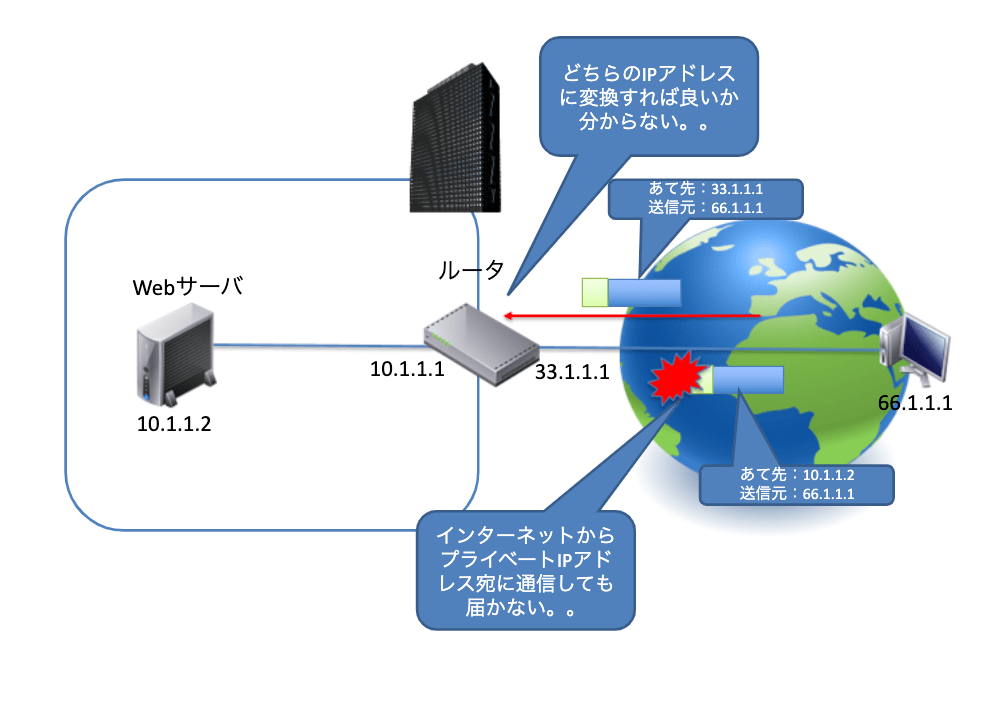
ここまでLAN側のPCからインターネットへのアドレス変換について書いてきましたが、インターネットからLAN側にあるPCへの通信はどうでしょうか?まずLAN側のIPアドレスはプライベートIPアドレスですから、そのままプライベートIPアドレス宛に通信を使用としても、そのパケットはインターネット上で破棄されてしまい通信できません。それではルータが保持しているグローバルIPアドレス宛に通信をするとどうなるでしょうか?
この方法でも通信はできません。ルータがパケットを受け取っても、そのパケットをLAN側のどのPCのアドレスに変換すればよいか判断することができないため、やはりパケットは届かないのです。このようにアドレス変換を使用すると、インターネット上からLAN側へ接続するようなアプリケーションは使用することができません。例えばLAN側にWebサーバを構築して、インターネット上から接続したいときに弊害が発生します。
アドレス変換の弊害を取り除く
アドレス変換を使用すると、インターネット上からLAN側へ接続するようなアプリケーションは使用することが出来ないのですが、これだとWebサーバをインターネットに公開したいなんて人にとってはアドレス変換は使えないことになってしまいます。そこで、そんな弊害を取り除くための機能が用意されています。この機能のことを「ポートフォワーディング」といいます。
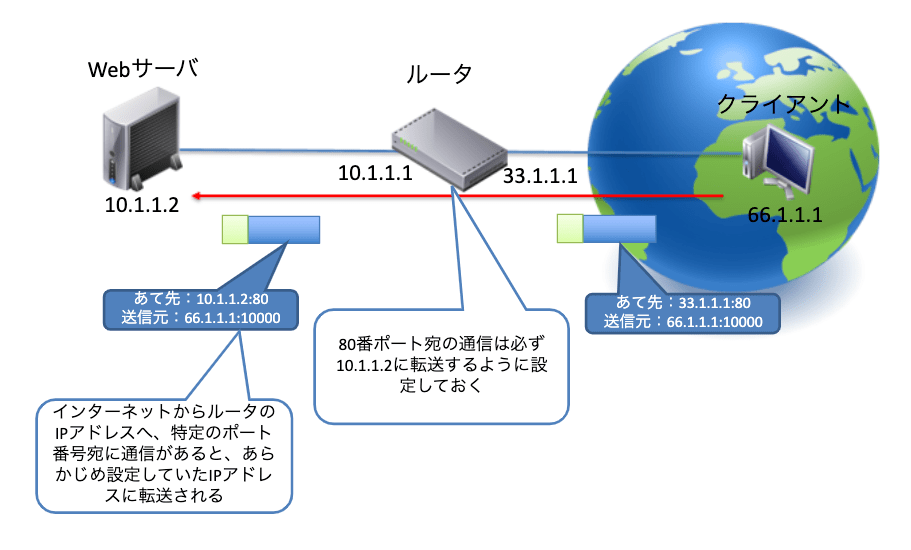
ポートフォワーディング
ポートフォワーディングは、インターネットから特定のポート番号宛にパケットが届いたときに、あらかじめ設定しておいたLAN側の機器にパケットを転送する機能です。通常のNAPT(IPマスカレード)の場合、LAN側からインターネット向けにパケットが送信されると、送信元のIPアドレスとポート番号を付け替えて、変換テーブルに記録することでアドレス変換をします。
ポートフォワーディングの場合は、「宛先ポートが80宛のパケットは、LAN側の192.168.1.1のPCへ転送する」といった内容を手動で設定します。こうすることで、インターネットからブロードバンドルータのIPアドレスへポート80宛のパケットが飛んできたときに、192.168.1.1のPCへ転送してくれます。
NAPTは安全?
NAPTを設定すると、外部からLAN側にあるノードへの通信が出来ないため、セキュリティの向上のために導入する企業もあるようです。NAPT自体はセキュリティのための機能ではなく、ネットワーク同士をつなぐための機能ですが、セキュリティの向上にも効果があります。
NAPTが動作しているルーターでは、外部からの不正なパケットをLAN側に通さずに破棄します。また、LAN側にあるノードのIPアドレスを外部に漏らさないため、悪意のある攻撃者はLAN内部のノードを特定した攻撃をすることができません。そのためある程度のセキュリティの向上は期待できますが、正しいパケットを装った不正なパケットを見分けることは出来ないため、万全なセキュリティ対策ではありません。さらにセキュリティを強化するには、後述するファイアウォールなどを機能が必要になります。
トランスポート層で動作する機器
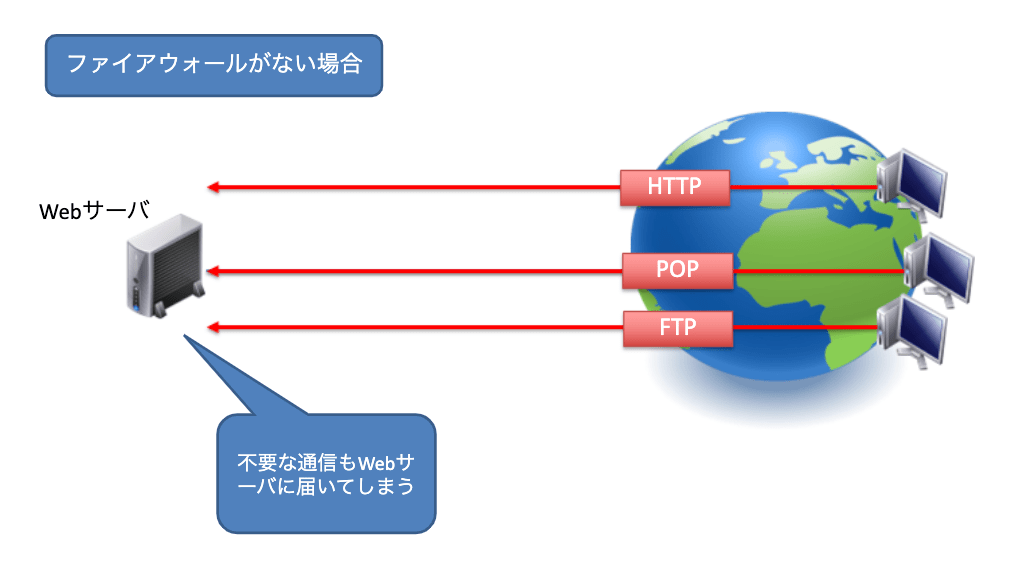
トランスポート層で動作する機器として、「ファイアウォール」があります。ファイアウォールはネットワーク層のIPアドレスとトランスポート層のポート番号をもとに通信の制御を行う機器です。あらかじめ事前に設定しておいたルールに従って正常とされる通信のみを通過させ、それ以外のパケットを破棄するという動作を行います。
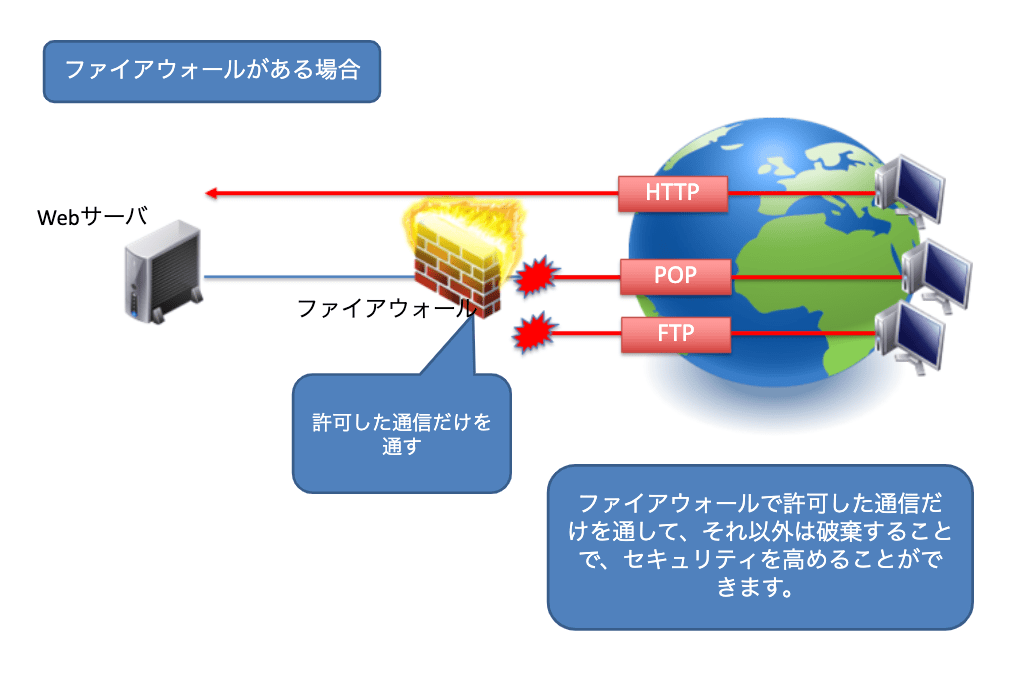
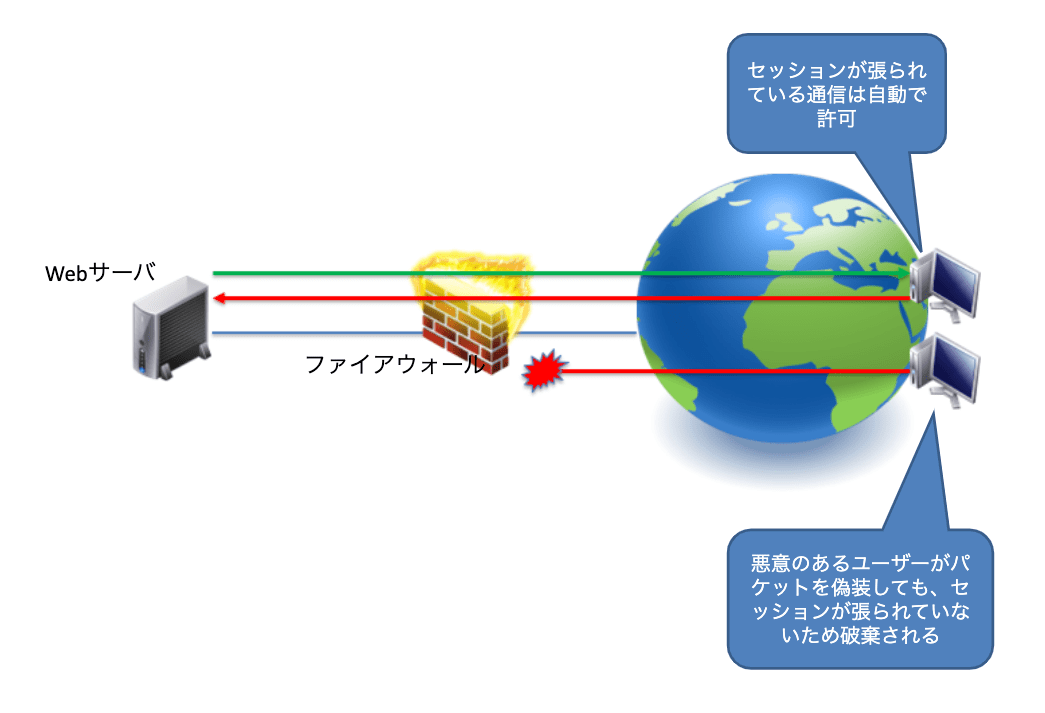
ステートフルインスペクション
ファイアウォールは「ステートフルインスペクション」という機能でパケットを制御します。「ステートフルインスペクション」とはパケットの状態をチェックし、動的にポートの開閉をしてくれる機能です。例えば、TCPの通信は双方向の通信であるため、送信元から宛先へのTCP通信について、必ず戻りのパケットが存在します。そのため通常ファイアウォールにも戻りのパケットに対しても通信の許可を指定してあげなければいけません。ステートフルインスペクションが無い場合、TCPのACKフラグが付いているパケットのみ許可する設定を行う必要があります。しかしこれだと、悪意のあるユーザがACKフラグを付けた攻撃パケットを送りつけるとファイアウォールを通過してしまう問題がありました。
ステートフルインスペクション機能が搭載されたファイアウォールの場合、TCPのセッション情報を認識して、セッションを確立しようとしている戻りのパケットのみを自動で許可してくれます。そのため、わざわざ戻りのパケットについてのルールを追加する必要もありませんし、外部からの攻撃も最小限に止めることも可能になります。またTCPではなく、UDPについても「ステートフルインスペクション」は有効です。送信元ホストから宛先ホストへのUDP通信が発生した場合、宛先ホストから送信元ホストへの通信を一定時間許可してくれます。例えば、DNSサービスをUDPで使用していた場合、ホストからDNSサーバへ名前解決のパケットを送ると、DNSサーバからホストへの返答メッセージが返されます。この通信もステートフルインスペクション機能があれば、自動で許可してくれます。
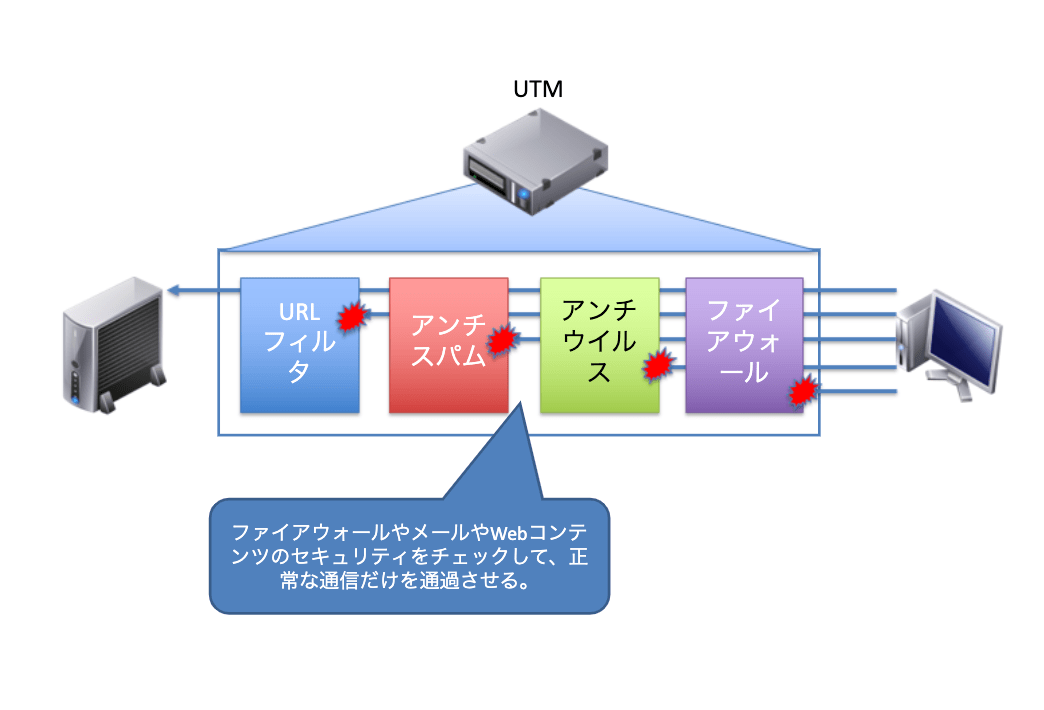
ファイアウォールから統合セキュリティ製品へ
ファイアウォールは現在でも多くの機能盛り込みが進められていて、最近はUTM(Unified Threat Management)と呼ばれる、ファイアウォールやVPNゲートウエイの機能に加えて、メールやWebコンテンツのセキュリティをチェックする機能などを搭載した統合的なセキュリティ装置も出てきています。
関連記事
検索
特集


著書




おすすめ記事