Dockerコンテナの仕組み -namespace、cgroup、overlayfs-
ここまでDockerを使ったコンテナの操作について説明してきました。今回はコンテナの要素技術について解説していきます。
Dockerコンテナの特徴には次のようなものがあります。
- コンテナのシステムリソースの隔離
- ファイルのレイヤ構造
- コンテナ間の通信
Dockerコンテナでは上記機能を実現するためにいくつかのLinuxが持つ機能を利用しております。主要なものとして以下の3つがよく挙げられます。
- overlayfs
- namespaces
- cgroups
ここらからコンテナの3つの特徴を実現するための要素技術について見ていきたいと思います。
コンテナのシステムリソースの隔離機能
コンテナはOSカーネルが持っている環境を隔離する機能を使っています。コンテナごとに、1つの仮想マシンのように独立した環境を持つことが可能です。
利用可能なリソースもコンテナごとに制限されていて、必要以上のリソースを利用することが出来ない仕組みになっています。
これらの隔離機能には、次のOSカーネルの機能が使われています。
- namespaces
- cgroups
namespaces
namespacesはコンテナを1つの仮想マシンのように占有されたシステムとして見せるためのLinuxカーネルの機能になります。namespace内のプロセスは他のnamespace内のプロセスとリソースが隔離されていて、プロセスごとの環境を構築することが可能です。
このnamespacesを採用することで、プロセス単位で他のプロセスに影響を与えること無く、環境を構築できるようになります。ここで構築された環境は、他のLinux上で同じ環境を再構築することができます。
namespaceで隔離できるリソースには次のようなものがあります。
- ユーザー/グループ
UID(ユーザーID)/GID(グループID)を分離する。異なるnamespace(名前空間)で同じUIDのユーザーを作成可能。 - マウントポイント
各プロセスが隔離されたマウントポイントを持つことができ、異なるnamespace(名前空間)のファイルシステムにアクセスできないようにする。 - プロセスツリー
PID(プロセスID)空間を分離する。異なるnamespace(名前空間)で同じPIDのプロセスを作成可能。 - プロセス間通信
IPC(Inter-Process Communication:プロセス間通信)リソースで使用する、IPCオブジェクトやメッセージキューなどを分離する。異なるnamespace(名前空間)の共有メモリなどにアクセスできないようにする。 - ホスト/ドメイン名
ドメイン名ホスト名を分離する。 - ネットワークスタック
ネットワークデバイスやIPアドレス、ルーティングテーブルなどのネットワークインタフェースを分離する。
Docker環境でnamespaceの動作を試してみる
まずは、ubuntuのコンテナを起動して、psコマンドを実行します。
❯ docker run -it --rm ubuntu ps
PID TTY TIME CMD
1 pts/0 00:00:00 psこの場合は、自身のコンテナ上のプロセスしか表示されません。
続いて、事前に「sshd」コンテナを起動させておいて、そのコンテナのPID namespaceを共有させる設定をして、psコマンドを実行してみます。
❯ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c0e248ab94fb docker_demo "/usr/sbin/sshd -D" 32 seconds ago Up 31 seconds 22/tcp elegant_swanson
❯ docker run -it --rm --pid container:c0e248ab94fb ubuntu ps
PID TTY TIME CMD
1 pts/0 00:00:00 sshd
6 pts/0 00:00:00 psPIDを共有させた場合、sshdのコンテナで動いているプロセスも確認することができます。
cgroup
Dockerでは、コンテナ内からアクセス可能なシステムのリソース(CPUやメモリなど)を厳密に制限しています。これを実現させるために、Linuxカーネルの機能であるcgroupを利用しています。
cgroupは、タスクをグループ化したり、グループ内のタスクに様々なリソース制御を行う仕組みです。先程のnamespaceはホスト名やPIDなどのリソースを制御する仕組みですが、cgroupはCPUやメモリなどの物理的なリソースを制御します。
制御可能なリソースは/sys/fs/cgroup以下に仮想的なファイルシステムが提供されていて、ここでファイル/ディレクトリ操作をすることで様々なリソース制御を行うことが可能です。
$ ls -l /sys/fs/cgroup
合計 0
dr-xr-xr-x 5 root root 0 10月 8 2018 blkio
lrwxrwxrwx 1 root root 11 10月 8 2018 cpu -> cpu,cpuacct
dr-xr-xr-x 5 root root 0 10月 8 2018 cpu,cpuacct
lrwxrwxrwx 1 root root 11 10月 8 2018 cpuacct -> cpu,cpuacct
dr-xr-xr-x 2 root root 0 10月 8 2018 cpuset
dr-xr-xr-x 5 root root 0 10月 8 2018 devices
dr-xr-xr-x 2 root root 0 10月 8 2018 freezer
dr-xr-xr-x 2 root root 0 10月 8 2018 hugetlb
dr-xr-xr-x 5 root root 0 10月 8 2018 memory
lrwxrwxrwx 1 root root 16 10月 8 2018 net_cls -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 10月 8 2018 net_cls,net_prio
lrwxrwxrwx 1 root root 16 10月 8 2018 net_prio -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 10月 8 2018 perf_event
dr-xr-xr-x 5 root root 0 10月 8 2018 pids
dr-xr-xr-x 5 root root 0 10月 8 2018 systemdDocker環境でcgroupの動作を試してみる
Docker環境で、cgroupの動作を確認してみます。分かりやすいところで、CPUとメモリの制御を行ってみましょう。
DockerでCPUやメモリを制御するコマンドオプションには以下のようなものがあります。
| オプション | 概要 |
|---|---|
| –cpuset-cpus | 使用するCPUコアを指定する |
| –cpu-shares | CPU時間の割り当てを相対比率で指定、デフォルト 1024 |
| -m | メモリ使用量を指定 |
例えば、2つのDockerコンテナを、–cpu-sharesオプションを使用して次のように起動した場合、centosの方がubuntuよりも2倍の優先度でCPU時間を割り当てられます。
sudo docker run --cpu-shares=1024 ubuntu
sudo docker run --cpu-shares=2048 cnetosファイルのレイヤ構造
Dockerコンテナのイメージはレイヤ構造をしているという解説を「Dockerイメージのレイヤの考え方とイメージの軽量化について」でしました。
このレイヤ構造により、コンテナを軽量化することが可能になり、同一ノード上で動く複数のコンテナが、Docker イメージを構成するイメージレイヤを共有することを可能にし、トータルとしてのコンテナサイズを最小化しています。
この仕組みを使うためにDockerでは、overlayfsという仕組みを採用しています。overlayfsはユニオンファイルシステムの1つで、ディレクトリを重ね合わせて1つのディレクトリツリーを構成できます。overlayfsは、上位層と下位層をマージっして1つのファイルシステムとして見せる仕組みで、ディレクトリはマージ、その他のファイルは上位層にあるファイルだけ見え、上位層がなければ下位層にあるファイルが見えます。
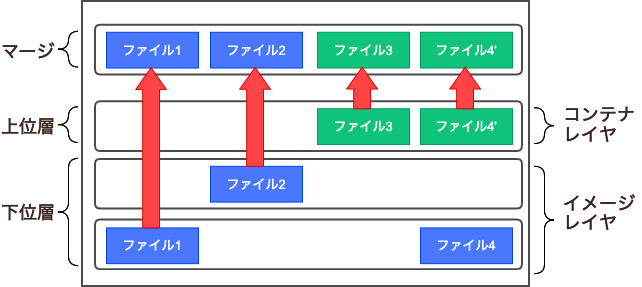
overlayfsの動作を試してみる
実際にoverlayfsの動作を確認してみます。
上図のように、2つのレイヤのディレクトリを準備して、ファイルを作成します。
$ mkdir upper lower
$ echo "lower a" > ./lower/a
$ echo "upper a" > ./upper/a
$ echo "lower b" > ./lower/b
$ echo "upper c" > ./upper/c
$ tree ./
./
├── lower
│ ├── a
│ └── b
└── upper
├── a
└── cファイルの作成が完了したら、mountコマンドでoverlayfsでマウントします。その際に、-tオプションでoverlayを指定、-oオプションでレイヤに対応させるディレクトリを指定、さらに作業用ディレクトリと結果を反映させるディレクトリを指定します。
# 作業用ディレクトリ(work)と結果を反映させるディレクトリ(mearge)を作成
$ mkdir work merge
# マウントします
$ sudo mount -t overlay overlay -o lowerdir=lower,upperdir=upper,workdir=work merge
# dfコマンドで確認
$ df merge/
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 30428648 11194100 19218164 37% /home/hoge/test/merge
# lsコマンドでファイル確認
$ ls -l merge/
合計 12
-rw-rw-r-- 1 root root 8 2月 10 14:49 a
-rw-rw-r-- 1 root root 8 2月 10 14:49 b
-rw-rw-r-- 1 root root 8 2月 10 14:50 c
# treeコマンドでも確認
akitbook@instance-1:~/test/overlayfs$ tree merge/
merge/
├── a
├── b
└── c
0 directories, 3 files
# catコマンドで上位層のファイルが見えていることを確認
akitbook@instance-1:~/test/overlayfs$ cat merge/a
upper a
akitbook@instance-1:~/test/overlayfs$ cat merge/b
lower b
akitbook@instance-1:~/test/overlayfs$ cat merge/c
upper c今回は2層で確認しましたが、DockerコンテナではDockerfileで指定された命令行ごとにレイヤが生成されますので、もっと多くのレイヤをoverlayfsでマージされて、1つのファイルシステムとして見えるようになります。
「Dockerイメージのレイヤの考え方とイメージの軽量化について」でも簡単に解説しましたが、コンテナ実行時にファイルの作成や変更を行った場合、下位レイヤ(イメージレイヤ)には変更は加えられず、上位レイヤ(コンテナレイヤ)にあるファイルに変更が加えられます。
例えば「ファイルa」を更新してみると、上位層のディレクトリ(upper)のファイルだけが更新されます。
$ echo "commit a" > ./merge/a
$ cat merge/a
commit a
$ cat upper/a
commit a
$ cat lower/a
lower a次に下位層ディレクトリ(lower)にしか存在している「ファイルb」を更新してみます。
# ファイル更新前には「upper」ディレクトリに「ファイルb」は存在しない
$ ls upper/
a c
$ echo "commit b" > ./merge/b
# ファイルを更新すると上位層ディレクトリ(upper)にファイルがコピーされ、更新される
$ ls upper/
a b c
$ cat upper/b
commit bこのように追加/修正された差分は上位層にあるファイルが更新され、ファイルが無い場合は下位層ディレクトリからコピーされ、更新されます。
関連記事
検索
特集


著書




おすすめ記事